Crear tablas comparativas de productos escalables para eCommerce
Crear tablas comparativas de productos escalables para eCommerce
Deja de actualizar gráficos estáticos manualmente. Una guía basada en datos para crear tablas comparativas de productos escalables y dinámicas que aumentan la conversión y reducen las devoluciones.
Preguntas frecuentes
Respuestas rápidas a las dudas más comunes.
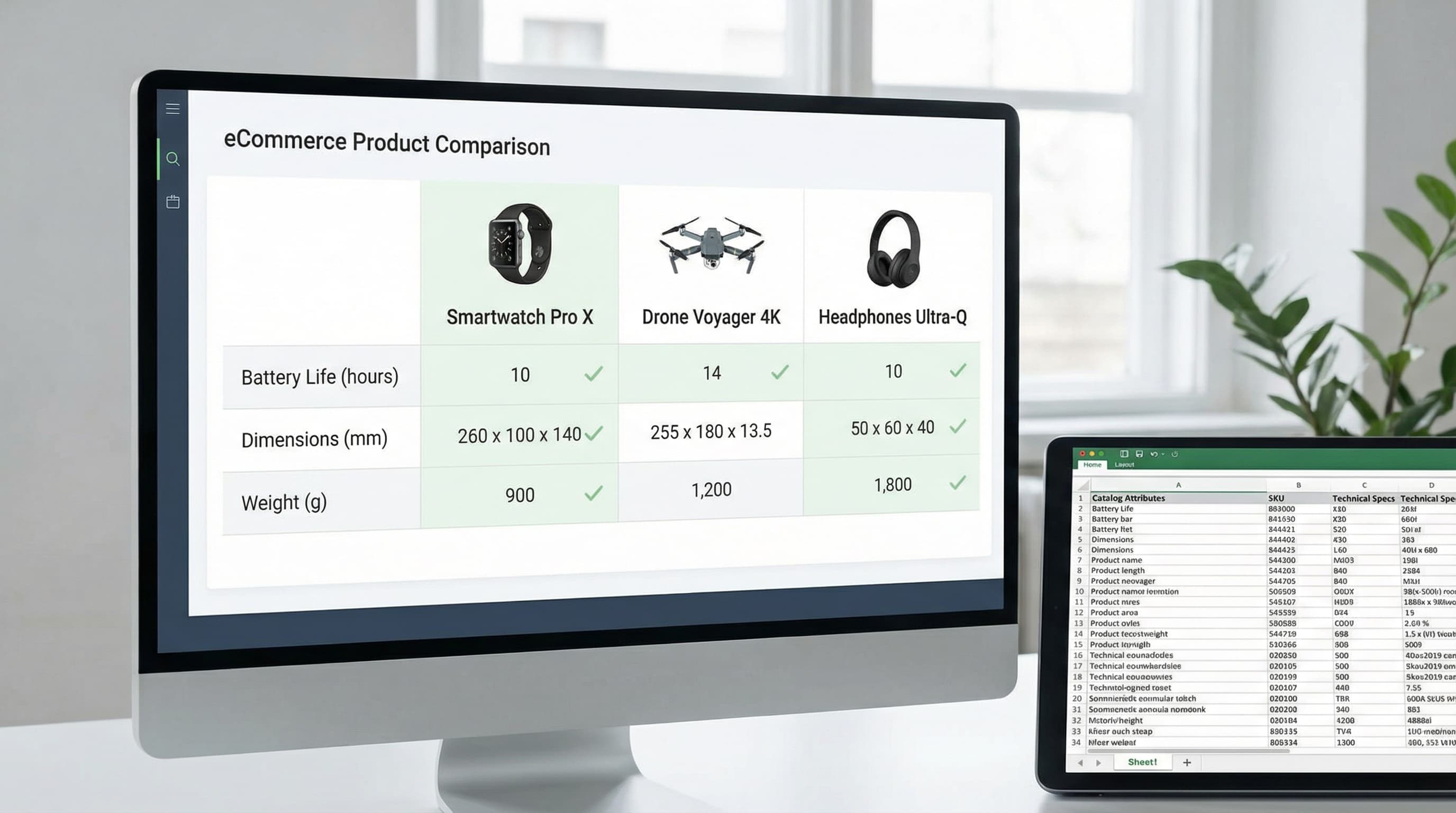
Las tablas comparativas de productos son el antídoto práctico contra la parálisis por elección en las páginas de producto. Cuando se construyen a partir de atributos del catálogo, presentan hechos consistentes y comparables que aceleran las decisiones, reducen las devoluciones y aumentan la conversión al hacer visibles las diferencias en lugar de ocultarlas.
El exceso de opciones en las compras online conduce a la fatiga decisional y a un mayor abandono. Un enfoque de tablas comparativas basado en datos trata la tabla como una vista en vivo del modelo de atributos, no como un bloque estático de texto manual. Esto mantiene las especificaciones precisas a medida que cambian el inventario y las variantes, y evita afirmaciones contradictorias entre los listados y los feeds. La investigación sobre comparaciones de productos explicables destaca la importancia del soporte estructurado a la decisión.
Cómo afecta esto en la práctica: Una tabla alimentada por atributos canónicos en tu PIM (sistema de Gestión de Información de Producto) o feed de catálogo reduce las devoluciones al alinear las expectativas con la realidad del producto. El mismo conjunto de atributos puede alimentar módulos en la PDP (página de detalle de producto), comparaciones en páginas de colección y exportaciones a marketplaces, por lo que el trabajo de contenido se hace una vez y se reutiliza.
Estrategia: Cuándo usar tablas comparativas de productos
Despliega tablas comparativas cuando los compradores se enfrenten a decisiones difíciles o exceso de opciones. Una comparación basada en datos del catálogo escala mejor que los gráficos manuales y reduce las devoluciones al mostrar diferencias objetivas de especificaciones desde el principio.
Identifica categorías de alta elección
Las categorías con muchas opciones necesitan comparaciones estructuradas porque los clientes deciden por atributos, no solo por marca. Céntrate en verticales con especificaciones complejas como electrónica de consumo, belleza con ingredientes clave, B2B e industrial donde la compatibilidad importa, y categorías con muchos SKUs y rotación frecuente de características.
Descubre porqué otras tiendas online confían en ButterflAI para acelerar sus ventas
Combina la profundidad de atributos de tu PIM con señales operativas como devoluciones y tickets de soporte para priorizar categorías. Un umbral práctico es etiquetar categorías que exponen más de cinco atributos de decisión en tu modelo de datos y muestran una tasa de devolución superior a la media. Evita construir tablas para categorías simples donde el detalle de atributos añade ruido en lugar de claridad.
Define tipos de tablas y alcance
Diferentes compradores necesitan diferentes niveles de detalle y enfoque para decidir eficientemente.
Matrices modelo-a-modelo: Lo mejor para compradores técnicos (ej. portátiles, piezas industriales).
Módulos Bueno/Mejor/Lo Mejor: Ideal para compradores que buscan orientación rápida sobre los más vendidos.
Extrae las filas de campos de atributos canónicos en tu PIM o feed de productos para que la comparación esté impulsada por una única fuente de verdad en lugar de texto manual.
PIM: Un sistema para centralizar atributos de productos y asegurar datos consistentes en todos los canales.
Metafields de Shopify: Campos personalizados por producto utilizados para almacenar atributos estructurados importantes para renderizar tablas.
Product Feed: Un formato de exportación que sindica atributos estructurados a marketplaces.
Estrategia de ubicación UX
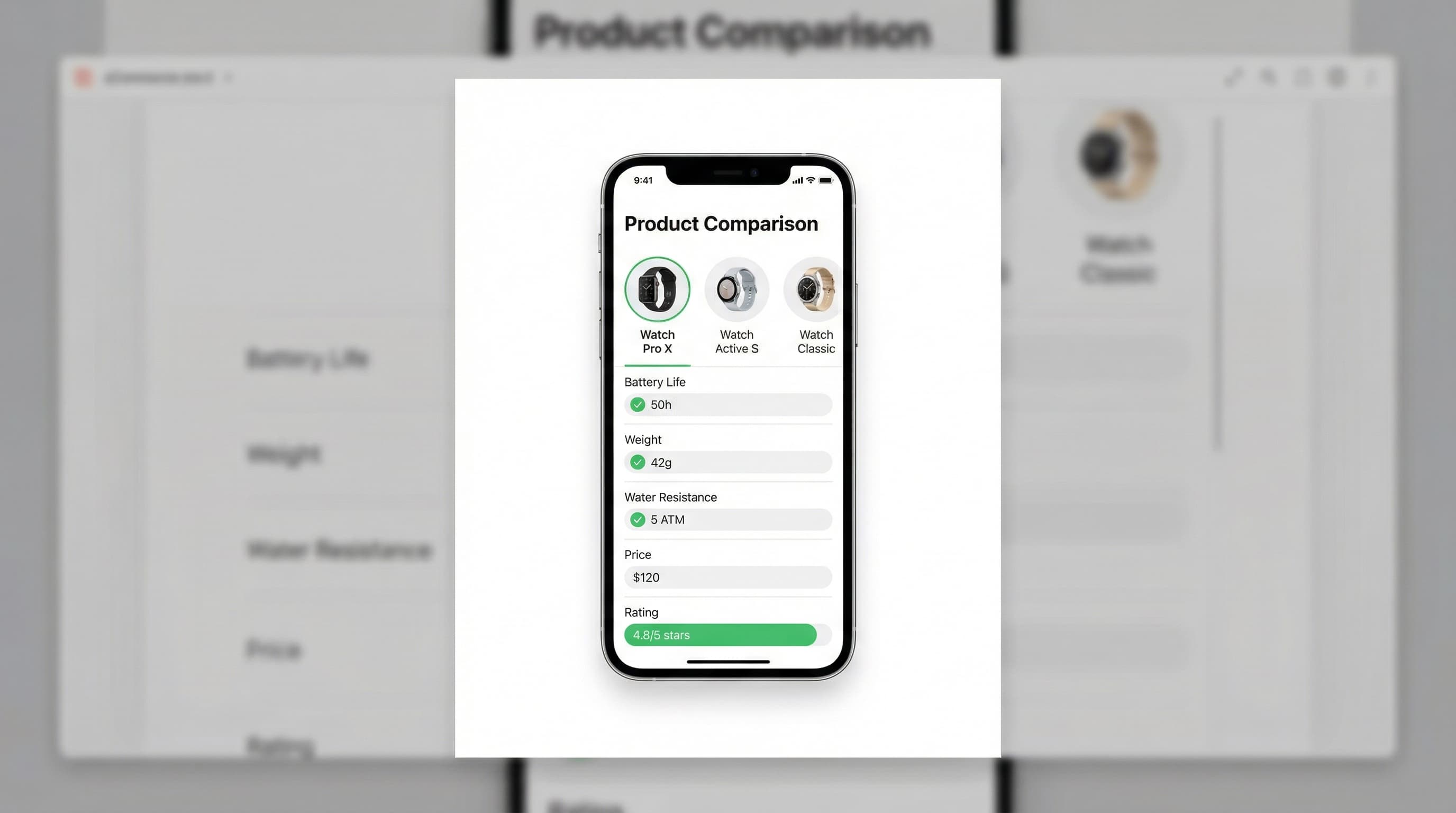
La ubicación afecta la intención del usuario y la conversión porque la profundidad y el momento de la comparación importan. Coloca tablas concisas de "bueno/mejor/lo mejor" en la PDP por encima del pliegue (above the fold) o en una pestaña de comparación visible para decisiones rápidas. Reserva las matrices completas para páginas de aterrizaje de categoría o un centro de comparación para investigación profunda. Enlaza las tablas compactas de la PDP al centro de comparación para que los usuarios puedan expandir a una vista modelo-a-modelo.
Para profundizar en patrones de UX, el Baymard Institute proporciona una guía extensa sobre las necesidades de detalle del producto y la fatiga decisional.
El Modelo de Datos: Convirtiendo características en atributos comparables
Las tablas comparativas son tan útiles como los datos que las respaldan. Para construir tablas dinámicas y escalables que impulsen la conversión, trata las características como atributos estructurados, no como texto libre. Los atributos estructurados permiten ordenamiento determinista, filtros (faceting) y generación automatizada de tablas en PDPs, colecciones y exportaciones.
Por qué las tablas necesitan atributos estructurados
Los atributos estructurados convierten el texto de marketing en campos tipados que los componentes frontend, feeds y PIMs pueden consumir. Si usas Shopify, un metafield actúa como un par clave-valor para almacenar datos personalizados tipados en los productos, haciendo que los atributos sean recuperables a escala.
Definiendo un esquema de atributos
Un esquema claro evita la ambigüedad entre categorías y proveedores. Crea un modelo de atributos consciente de la categoría. Define un ID, nombre, tipo de dato, unidad, valores permitidos y alcance para cada atributo. Mantén los atributos atómicos: separa el valor numérico de la unidad.
Ejemplo de entrada de atributo:
ID:peso
Tipo:número
Unidad:gramo
Alcance:global
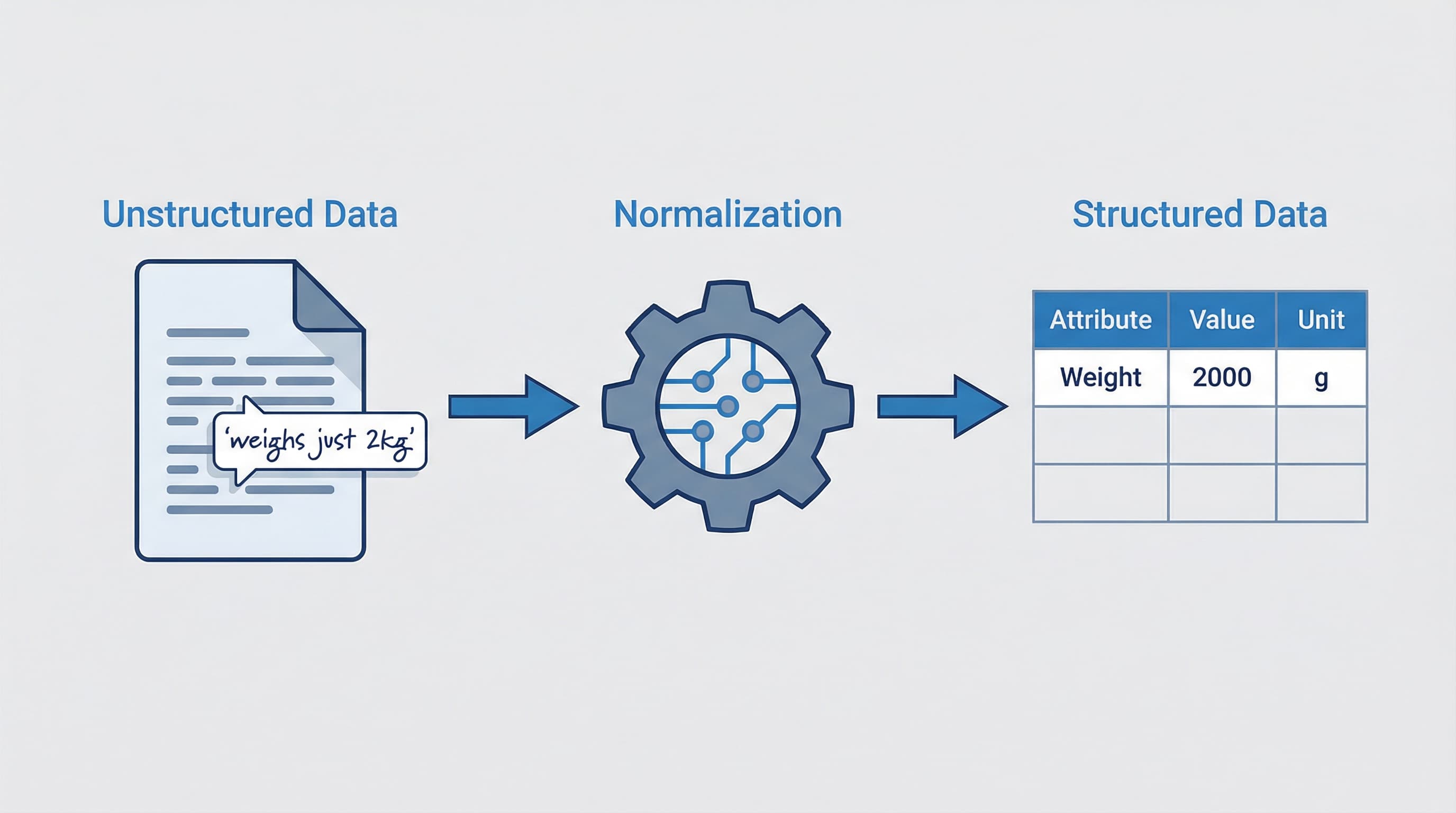
Unidades y normalización
La discrepancia de unidades es una fuente común de comparaciones engañosas. Almacena un valor numérico canónico más un código de unidad. Normaliza al ingerir a una unidad canónica por dimensión (ej. convertir longitudes a milímetros). Persiste la unidad original para visualización y mantén una pequeña tabla de conversión con registros de auditoría.
Ejemplo: Transformar "1.5 metros" a "1500 milímetros". Almacenar valor canónico 1500, unidad milímetro.
Booleanos y enumeraciones
Los booleanos y enums permiten comparaciones claras de sí/no y filtros. Usa tipos booleanos explícitos para características binarias y enumeraciones para atributos de opciones múltiples. Mapea los términos del proveedor a tu vocabulario controlado usando tablas de búsqueda. Usa null para "desconocido" en lugar de false para evitar falsos negativos.
Ejemplo:
Atributo:resistente_agua
Tipo:booleano
Valores:true, false, unknown
Manejo de datos faltantes y políticas de fallback
Los valores faltantes degradan la confianza y pueden aumentar las devoluciones si los compradores asumen que existen características donde no las hay. Define una política de fallback (reserva) por atributo y canal. Las opciones incluyen mostrar "N/A", ocultar el atributo o inferir con valores predeterminados conservadores (anotados con fuente y confianza para QA interno).
Checklist de QA para evitar especificaciones engañosas
La automatización ligera y el muestreo reducen correcciones costosas. Automatiza validaciones para tipos, unidades, rangos y enumeraciones. Añade revisión humana para atributos de alto impacto y rastrea excepciones. Por ejemplo, marca un producto si la capacidad de la batería cae fuera de los límites esperados.
Diseñando para la Conversión: Móvil y Patrones UX
Las tablas comparativas deben estar impulsadas por datos y diseñadas para reducir la fricción en la decisión.
Responsividad móvil
La mayoría de las sesiones ocurren en móvil, por lo que las tablas deben refluir sin ocultar especificaciones clave. Usa tarjetas apiladas para pantallas estrechas o deslizamiento horizontal con una columna de nombre de producto fijada. Prioriza tres atributos de decisión en vistas pequeñas y ofrece un control de expansión para detalles completos. La divulgación progresiva mantiene la presentación inicial escaneable mientras preserva el conjunto de datos completo para usuarios que quieren profundizar.
Encabezados fijos y alineación de columnas
Los usuarios necesitan orientación al escanear matrices largas. Fija el encabezado y la columna izquierda del producto para mantener el contexto mientras los usuarios hacen scroll. Usa anchos de celda proporcionales y separadores sutiles para que los valores se alineen a través de las filas. Prueba el comportamiento fijo tanto en iOS como en Android y mantén los objetivos táctiles grandes.
Destacando diferencias vs similitudes
Los compradores deciden más rápido cuando los contrastes son obvios. Enfatiza las celdas diferentes con un tinte de color o mayor peso, añade insignias en línea para características únicas y proporciona un interruptor para mostrar "solo filas diferentes". Usa microcopy breve para explicar por qué importa una diferencia para que los usuarios no malinterpreten pequeñas variaciones.
Reducir la sobrecarga cognitiva
Las tablas densas causan parálisis por elección. Agrupa atributos en categorías nombradas (ej. Rendimiento, Dimensiones, Garantía), muestra una fila de resumen compacta con los criterios de decisión principales y usa iconos para atributos recurrentes. Aplica divulgación progresiva para revelar detalles bajo demanda y enlaza cada afirmación a la fuente de especificación canónica para mejorar la confianza.
Escalando la Producción con IA y Operaciones de Catálogo
Esta sección explica cómo operacionalizar la construcción de tablas comparativas a partir de atributos estructurados usando IA y automatización. Céntrate en pipelines que extraen atributos, aplican reglas de normalización y generan explicaciones cortas legibles por humanos.
Pipeline de extracción de atributos
Obtener atributos consistentes es la base de tablas comparativas fiables. Usa un pipeline híbrido que combine reglas de tu PIM con modelos de extracción ligeros para ingerir atributos de proveedores, feeds de vendedores y descripciones heredadas. Comienza definiendo un modelo de atributos canónico y mapeando los nombres de campos entrantes a ese modelo. Rastrea la procedencia para que cada celda en una tabla comparativa enlace de vuelta al atributo fuente y la confianza de extracción.
Ejemplo: Mapear campo de proveedor weight_oz y spec_wt al canónico weight_grams y convertir unidades durante la ingesta.
Reglas de normalización y canonicalización
La normalización convierte valores heterogéneos en hechos comparables. Define reglas de transformación para unidades, rangos, booleanos y enumeraciones. Implementa la normalización en el PIM o una capa ETL como funciones deterministas y registra los cambios.
Ejemplo: Normalizar tallas como "pequeña", "medium", "large" a códigos de talla numéricos mientras mantienes tanto la etiqueta original como el código canónico.
Explicaciones de especificaciones autogeneradas
Las explicaciones cortas reducen la confusión del cliente y disminuyen las devoluciones. Genera aclaraciones de una línea legibles por humanos para especificaciones técnicas usando plantillas y modelos NLG ligeros. Enlaza cada explicación al atributo original e incluye una puntuación de confianza para que QA pueda priorizar revisiones.
Ejemplo: Para clasificación impermeable 5 ATM, produce la explicación: "Resistente al agua hasta 50 metros; adecuado para ducharse y nadar en superficie."
De piloto a catálogo completo
Empieza pequeño con una categoría de alto impacto, valida las conversiones y el delta de tasa de devoluciones, luego expande usando mapeo automatizado. Asegura que tu checklist de QA cubra conversiones de unidades verificadas, valores booleanos estandarizados y revisiones para explicaciones automatizadas de baja confianza.
De Prototipos en Excel a Implementación Dinámica
Empieza prototipando tablas comparativas en Excel para validar qué atributos impulsan la conversión antes de construir un componente dinámico impulsado por PIM. Las hojas de cálculo son rápidas para la aprobación de los stakeholders, pero las plantillas estáticas fallan a medida que crecen los SKUs.
Prototipa la estructura de datos en Excel
Excel permite a los equipos acordar filas canónicas y tipos de atributos antes de que comience el trabajo de ingeniería. Crea una hoja de columnas canónicas con nombre de atributo, tipo, unidad, fuente y prioridad. Usa validación de datos para forzar vocabularios controlados y una hoja de filas de muestra con SKUs representativos para detectar casos borde temprano.
Mapea atributos a PIM y Metafields de Shopify
El mapeo previene la copia manual y permite el renderizado dinámico en todos los canales. Construye una matriz de mapeo desde las columnas canónicas de Excel a los IDs de atributos del PIM y los namespaces de metafields de Shopify. Esto reduce la ambigüedad y previene discrepancias de unidades al exportar a marketplaces.
Ejemplo: Atributo de Excel peso mapeado a pim.weight_g y shop.metafield.product.weight_grams.
Implementa QA y reutiliza el dataset
Las especificaciones incorrectas aumentan las devoluciones y dañan la confianza. Añade reglas de validación, un checklist de QA con reglas de muestreo y una puerta de publicación que bloquee productos con atributos obligatorios faltantes. Implementa la tabla comparativa como un componente que lee atributos dinámicamente del PIM o metafields para que el mismo dataset alimente módulos de PDP, filtros de colección y exportaciones.
Gobernanza: Checklist de QA y Métricas de Éxito
Las tablas comparativas deben reflejar atributos de catálogo autoritativos para evitar engañar a los compradores.
Auditoría de fuente de atributos
Verifica de dónde se obtiene cada especificación y quién es el propietario. Mapea cada columna de comparación a un campo único de PIM o sistema y rastrea la propiedad en un registro vivo. Esto evita el error de mapear columnas a texto de listado manual que a menudo varía.
Reglas de validación de datos
Previene valores imposibles, unidades mixtas y errores de formato. Fuerza tipos, unidades y normalización en el ETL que construye feeds y metafields. Por ejemplo, asegura que todos los valores de longitud se conviertan a milímetros antes de la comparación numérica.
Control de cambios y aprobación
Evita ediciones ad-hoc que rompan comparadores y analíticas. Protege los cambios de esquema detrás de PRs y requiere aprobación del propietario del catálogo y PM. Un error común es permitir ediciones tardías y no revisadas a los tipos de atributos.
Auditoría de precisión del consumidor
Reduce devoluciones y quejas realizando un muestreo mensual que concilie las especificaciones de la PDP con la documentación del proveedor y las medidas de almacén. Valida las dimensiones para una muestra de 50 SKUs para evitar sesgos.
Métricas de éxito
Rastrea el aumento de conversión de tests A/B, el delta de tasa de devolución para SKUs incluidos y la tasa de discrepancia entre exportaciones de PIM y PDP. La investigación de Salsify enfatiza la necesidad de precisión en el contenido para construir confianza con el consumidor.
Automatizando la extracción de atributos para tablas comparativas
Construir tablas comparativas fiables falla cuando los datos están fragmentados en PDFs, feeds desordenados y descripciones heredadas. ButterflAI detecta, extrae y normaliza atributos de productos desde fuentes no estructuradas, asegurando que tu PIM y Metafields de Shopify estén poblados con los datos limpios y estructurados necesarios para impulsar tablas comparativas dinámicas.