Qué es la gobernanza de datos de producto en eCommerce
La gobernanza de datos de producto es el sistema de reglas, roles y procesos que asegura que los atributos del producto sean precisos, coherentes y estén listos para todos los canales. En pocas palabras: gobernar los campos y flujos que alimentan los listados, filtros, feeds y páginas de detalles del producto (PDPs) para evitar rechazos, solucionar el caos de filtros y ofrecer experiencias confiables al cliente.
El alcance de la gobernanza de datos de producto
Por qué es importante: Centrar el alcance de la gobernanza estrictamente en lo que impulsa el descubrimiento y la compra por parte del cliente reduce la mayoría de los incidentes del catálogo sin crear cargas de trabajo innecesarias.
Qué gobernar:
Empieza con los niveles de atributos (obligatorios, recomendados, opcionales) y documenta el tipo de dato, los valores permitidos y ejemplos de formato para cada uno. Gobierna la lógica de las variantes con mapeo padre-hijo y reglas de herencia de SKUs para que atributos como talla y color se comporten de forma coherente en toda la tienda. Registra los identificadores únicos (GTIN, MPN, SKU interno) y mapéalos según los requisitos de cada marketplace o canal de anuncios. Define reglas de medios para la secuencia de imágenes principales, resolución mínima, tipo de archivo y convenciones de texto alternativo (alt-text). Por último, mapea los campos de origen con los campos del feed del canal y anota cualquier transformación aplicada durante la generación del feed.
Por ejemplo, al mapear identificadores únicos, Amazon requiere ASINs específicos o GTINs estándar, mientras que Google Merchant Center puede aceptar el MPN combinado con la Marca si no hay un GTIN disponible. Documentar estas reglas específicas de respaldo (fallback) evita rechazos masivos de feeds al lanzar nuevos canales.
Conceptos clave:
PIM: Sistema de Gestión de Información de Producto (Product Information Management) que centraliza atributos y medios del producto, actuando como tu única fuente de verdad.
Metafields de Shopify: Campos personalizados utilizados para almacenar datos adicionales de productos en Shopify; esenciales porque alimentan temas, filtros y aplicaciones de marketplaces.
Feed: Archivo estructurado o endpoint de API que exporta filas de productos a los canales; es crucial porque las filas inválidas provocan rechazos inmediatos.
Ejemplo:
Ejemplo de nivel de atributo: Obligatorio (Título, Precio, SKU, GTIN).
Error a evitar: Dejar los niveles sin definir, lo que permite que se publiquen productos incompletos y genera filtros facetados incoherentes en las páginas de colección.
Por qué fallan los catálogos
Los catálogos suelen fallar por problemas en los procesos, de mapeo o de falta de responsables, más que por la ausencia de una herramienta. Los identificadores faltantes o no válidos provocan el rechazo inmediato en canales estrictos. Los valores de atributos incoherentes (por ejemplo, "Marino", "Azul oscuro", "Azul") fragmentan los filtros y reducen la visibilidad. Un mapeo incorrecto de variantes crea listados duplicados o impide por completo el checkout. Una mala gestión de medios reduce la conversión y aumenta las devoluciones. Finalmente, los fallos de sincronización entre el PIM y la tienda, combinados con una falta de claridad sobre quién es el responsable, hacen que la solución sea muy lenta.
Inventariar los atributos existentes y asignarlos a niveles obligatorios, recomendados u opcionales.
Definir la lógica de las variantes y las reglas de identificadores padre-hijo.
Mapear los identificadores únicos por canal y documentar los campos de origen y las transformaciones.
Establecer reglas de nomenclatura de imágenes, texto alternativo y calidad.
Implementar reglas de validación y un flujo de trabajo para gestionar rechazos.
Asignar responsables por atributo y programar una validación diaria con un sprint semanal de resolución.
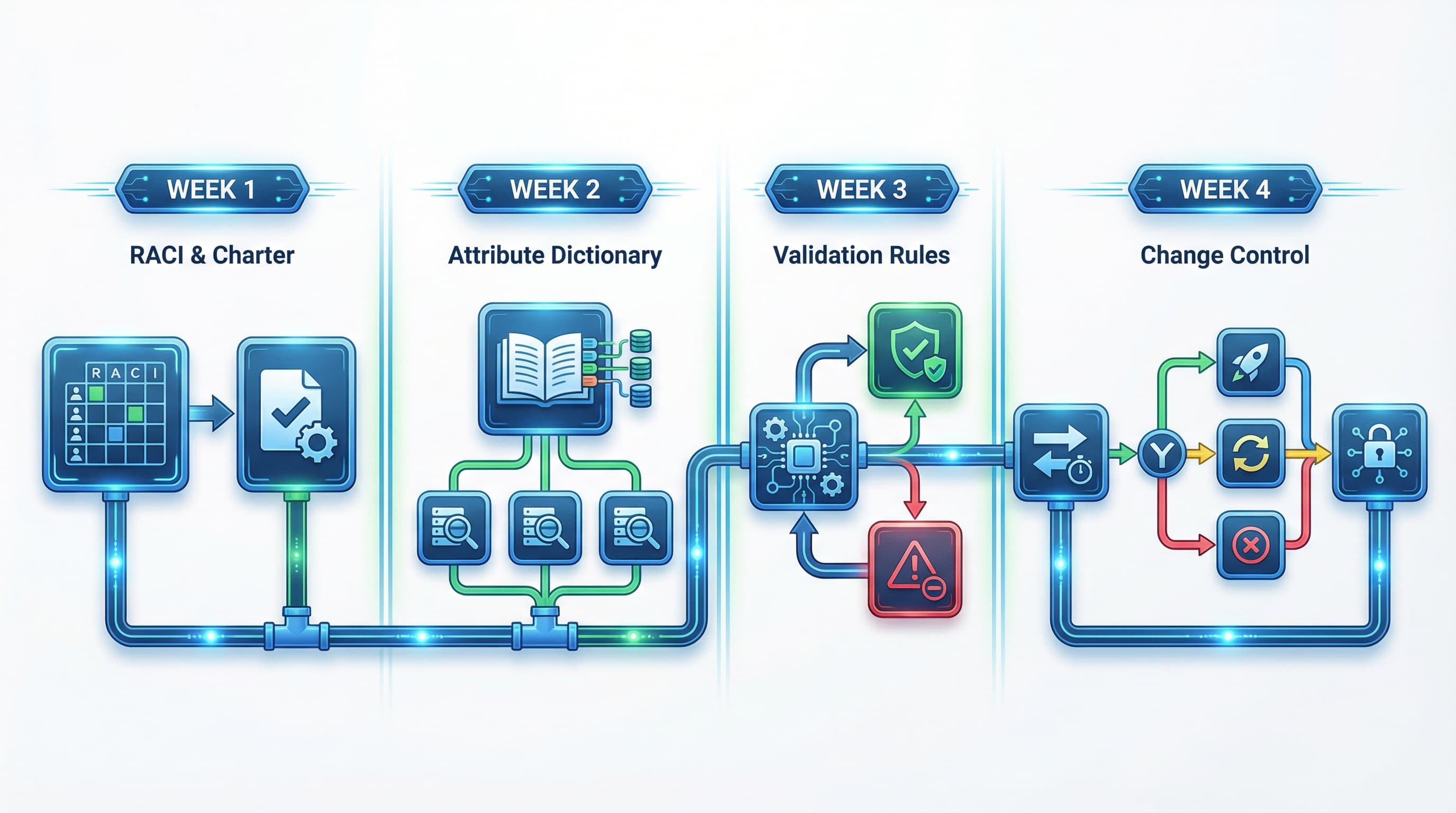
Plantilla de framework de gobernanza en 30 días
La mayoría de los problemas de catálogo comienzan con responsabilidades poco claras y atributos incoherentes. Esta plantilla de 30 días proporciona un plan compacto para construir un framework de gobernanza de datos de producto que detiene los rechazos de feeds, soluciona el caos de filtros y produce PDPs coherentes para web y marketplaces.
Semana 0: Configuración y alineación
Por qué es importante: La alineación rápida evita trabajo innecesario más adelante y reduce el tiempo dedicado a solucionar rechazos de marketplaces después del lanzamiento.
Cómo abordarlo: Nombra a un único responsable del catálogo y reúne a los stakeholders de merchandising, operaciones de contenido, ingeniería y adquisición pagada. Crea un espacio de trabajo compartido y exporta una muestra de 500 SKUs que representen la complejidad de tu catálogo (top ventas, artículos de baja rotación y productos orientados a marketplaces).
Ejemplo: Responsable del catálogo designado como Head of Catalog. Muestra exportada de Shopify y del PIM.
Error típico: No tener un único punto de contacto para decisiones de taxonomía, lo que lleva a debates interminables en comités.
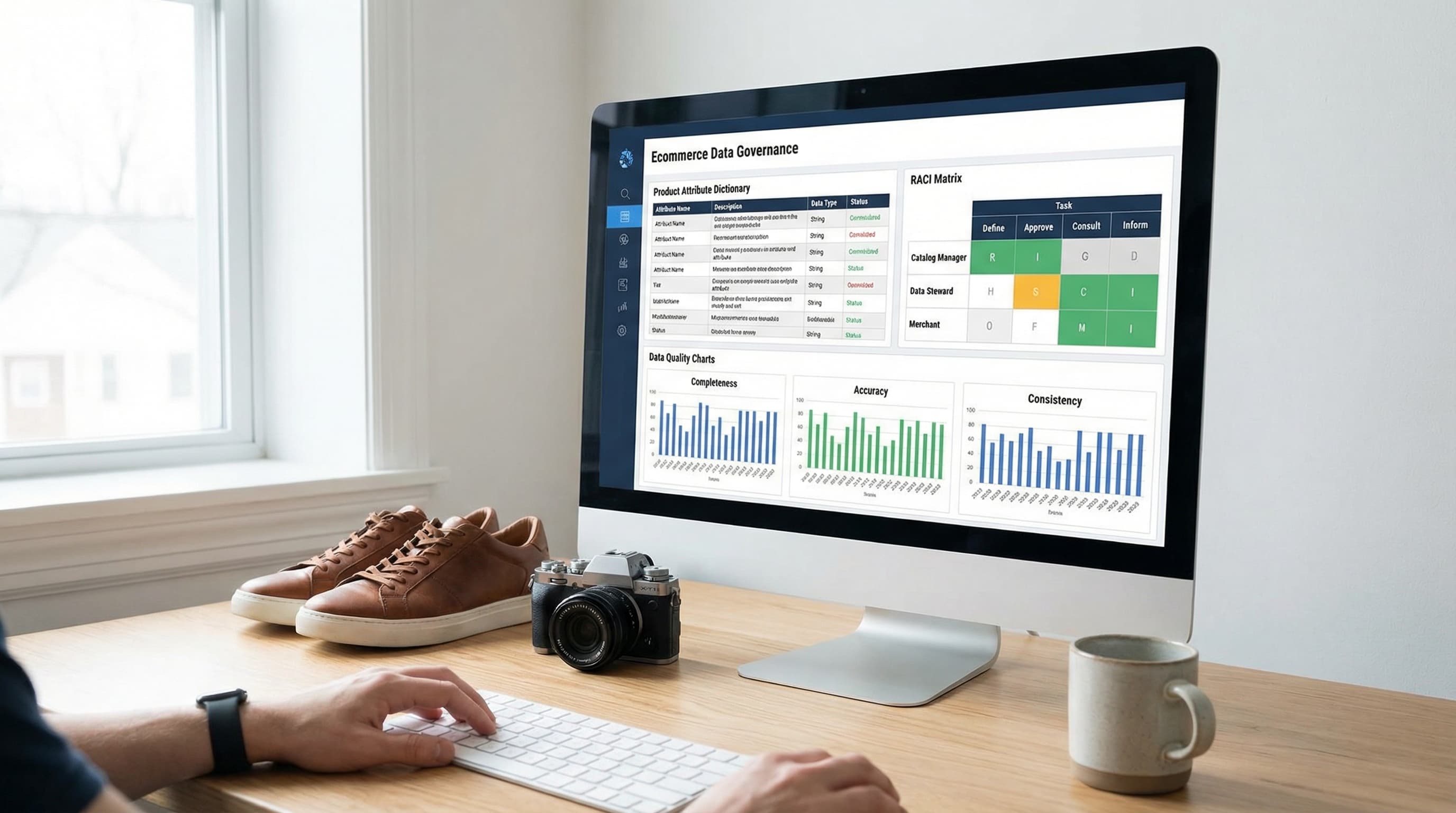
Semana 1: Construir la matriz RACI y el plan de gobernanza
Por qué es importante: Una matriz RACI aclara exactamente quién es responsable de la entrada de datos y quién aprueba los cambios en los atributos del producto.
Cómo abordarlo: Define los roles (Responsable, Aprobador/Accountable, Consultado, Informado). Incluye responsables específicos para la taxonomía de atributos, imágenes, GTINs y precios. Limita el alcance inicial a 10 atributos de alto impacto para mantener la agilidad: Título, Marca, GTIN, Categoría, Color, Talla, Materiales, Precio, Disponibilidad e Imagen Principal.
Ejemplo de matriz RACI:
Responsable (R): Especialista de catálogo (crea y actualiza valores).
Aprobador (A): Head of Catalog (asegura la calidad y aprueba cambios en la taxonomía).
Consultado (C): Merchandising y Legal (proporcionan input sobre claims y categorización).
Informado (I): Marketing y Adquisición Pagada (son notificados sobre cambios en la estructura del feed).
Error típico: Sobrecargar el rol Aprobador con demasiadas personas, bloqueando el flujo de trabajo.
Semana 2: Crear el diccionario de atributos
Por qué es importante: Un diccionario de atributos claro soluciona el caos de los filtros y garantiza una experiencia de búsqueda coherente en todos los canales.
Cómo abordarlo: Para cada atributo, haz una lista con su definición, tipo, formato, valores permitidos (o patrón regex), sistema de origen, prioridad, valor de ejemplo y regla de validación.
Fragmento de plantilla: Entradas del diccionario de atributos
Atributo: Título
Tipo: Texto
Formato: Oración (Title Case)
Valores permitidos: N/A (Texto libre, pero guiado por convención de nomenclatura)
Origen: PIM
Prioridad: Alta (Obligatorio)
Ejemplo: "Zapatilla de running para hombre - Malla ligera"
Validación: Debe coincidir exactamente con la lista permitida.
Error típico: Dejar los valores permitidos sin documentar para los atributos de faceta (como color o material), lo que da como resultado filtros desordenados en el frontend.
Semana 3: Implementar reglas de validación y testear feeds
Por qué es importante: Las reglas de validación detectan problemas antes de que los feeds lleguen a los canales externos, reduciendo drásticamente las tasas de rechazo.
Cómo abordarlo: Traduce las reglas de tu diccionario de atributos a validaciones automáticas dentro de tu PIM, capa de integración o herramienta de gestión de feeds. Las validaciones comunes incluyen la presencia obligatoria, patrones regex para GTINs, enumeraciones para rutas de categoría y comprobaciones de resolución de imágenes.
Ejemplo de reglas de validación:
GTIN: Regex para 8-14 dígitos numéricos.
Título: No vacío Y máximo 150 caracteres.
Imagen principal: Resolución mínima 800x800px.
Error típico: Ejecutar las validaciones solo al final del pipeline, lo que dificulta identificar qué sistema de origen introdujo el error. Para escenarios prácticos, revisa este artículo sobre cómo usar reglas de feed.
Semana 4: Control de cambios y despliegue
Por qué es importante: Los cambios controlados evitan desviaciones accidentales de la taxonomía y roturas inesperadas del feed durante los picos de ventas.
Cómo abordarlo: Implementa un flujo de aprobación ligero. Los cambios en el diccionario de atributos deben pasar por un ticket de aprobación que incluya una evaluación de impacto y SKUs de muestra. Programa un resumen semanal de cambios aprobados y ten siempre un plan de rollback (marcha atrás).
Ejemplo de flujo de aprobación:
Enviar ticket de cambio (ej. "Añadir 'Oversize' al atributo Talla").
El Responsable revisa con SKUs de muestra.
El Aprobador acepta o rechaza.
Desarrollo aplica el cambio y ejecuta la validación.
El equipo Informado recibe el resumen del despliegue.
Error típico: No tener un mecanismo de rollback ni un historial de versiones para las definiciones de atributos.
Mide el éxito: Realiza un seguimiento del recuento de rechazos de feed, las transacciones perdidas debido a rechazos y los tickets de quejas sobre facetas de filtros antes y después de la ventana de 30 días.
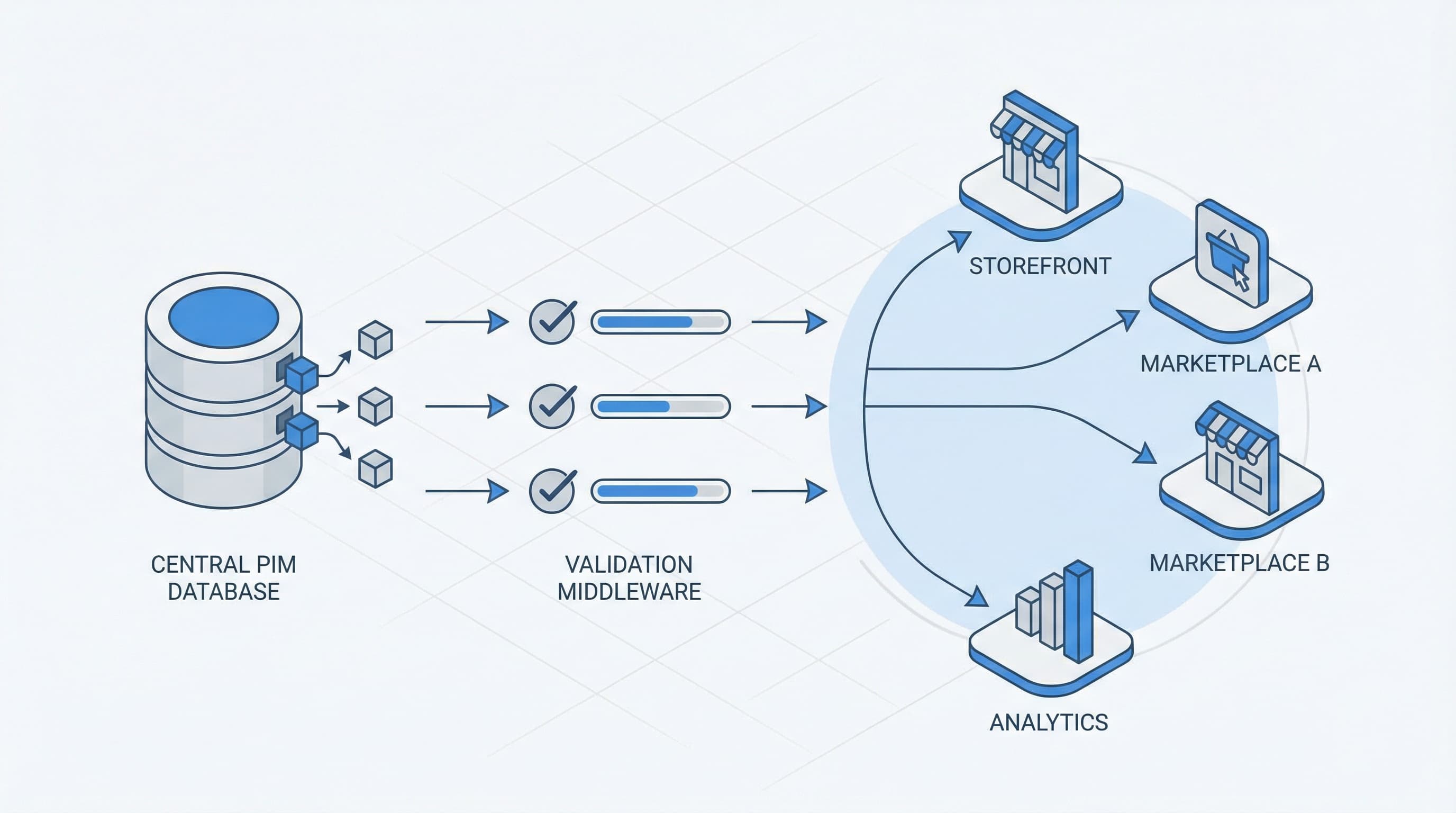
Arquitectura y herramientas de gobernanza de datos
La gobernanza de datos de producto debe ser ligera y pragmática. Una configuración pesada, a nivel puramente enterprise, ralentizará las operaciones de eCommerce. Esta arquitectura mantiene las reglas cerca de los puntos de autoría y añade un filtro final de seguridad antes de publicar en las tiendas.
El PIM como única fuente de verdad
Centralizar atributos, medios y taxonomías en un PIM asegura que los errores se corrijan solo una vez y no se repliquen en marketplaces o anuncios.
Enfoque común:
Aplicar definiciones de atributos y marcas de "obligatorio" de forma nativa en el PIM.
Usar un entorno de staging (pruebas) para las importaciones de proveedores y el enriquecimiento de datos antes de enviarlos al catálogo maestro.
Ejemplo:
El campo "Color" debe coincidir con un menú desplegable de vocabulario controlado (ej. Rojo, Azul, Negro) en la interfaz del PIM, impidiendo a los usuarios escribir "Azul Marino" si no está aprobado.
Error típico:
Validar los datos solo a nivel de tienda provoca PDPs incoherentes, ya que los datos de origen en el PIM siguen teniendo errores y sobrescribirán la corrección en la siguiente sincronización.
Dónde deben residir las reglas de validación
Pon las validaciones primarias en los sistemas iniciales (upstream) donde se crean los datos. Las validaciones primarias incluyen la presencia del atributo, comprobaciones del tipo de dato y el cumplimiento de los valores permitidos.
Mantén controles ligeros en el lado del servicio dentro de la capa de integración para verificar la integridad del mapeo e implementar reglas de negocio que sean estrictamente específicas del canal. Esto reduce las repetidas correcciones manuales en diferentes marketplaces.
Qué validar en origen (upstream):
Presencia de los atributos obligatorios.
Tipos de datos y unidades correctas (ej. peso es un número, la unidad es 'kg').
Recuento de imágenes, dimensiones mínimas y tipos de archivo correctos.
Integrar comprobaciones antes de publicar en Shopify
Un pipeline de datos práctico y resiliente se basa en tres filtros principales:
Captura y normalización en el PIM: La entrada inicial de datos está restringida por las reglas del diccionario.
Validación en la capa de integración: Comprueba el mapeo, los formatos del feed y las reglas de negocio antes de dar formato al payload.
Comprobación pre-publicación en staging: Un entorno de pruebas (staging) de Shopify que bloquea el envío en caso de fallo, evitando roturas en la tienda en vivo.
Si una comprobación previa a la publicación en staging falla debido a un metafield obligatorio ausente (como 'instrucciones_de_cuidado' para un tema de ropa), el pipeline debe detener la sincronización solo para ese SKU específico en lugar de fallar todo el lote, permitiendo que el resto del catálogo se actualice correctamente.
Esta arquitectura reduce el retrabajo al detectar errores en el punto más barato de solucionar (la entrada de datos) y mantiene las operaciones del catálogo centradas en la calidad de los datos en lugar de estar apagando fuegos a diario.
Escalar la calidad de los datos del catálogo y la automatización con IA
Los frameworks de gobernanza fallan si solo existen en hojas de cálculo. Escalar requiere convertir las reglas en flujos de trabajo operativos utilizando muestreo de QA, dashboards específicos y automatización segura.
Estrategia de muestreo de QA
Por qué es importante: El muestreo encuentra errores sistémicos antes de que lleguen a los feeds, protegiendo las puntuaciones de salud de tus canales.
Configura un muestreo aleatorio y basado en riesgos en todos tus sistemas de origen, categorías y tipos de cambios. El muestreo basado en el riesgo se centra en atributos de alto impacto como el precio, el GTIN y la disponibilidad. Implementa tareas de muestreo automatizadas en tu PIM o herramienta ETL que envíen los fallos directamente a un rastreador de incidencias (issue tracker).
Ejemplo: Un script nocturno selecciona 200 SKUs de 10 categorías de alto riesgo y marca cualquier atributo obligatorio que falte para su revisión manual a la mañana siguiente.
Error típico: Muestrear solo los más vendidos (best-sellers), lo que permite que se acumulen defectos en la larga cola (long-tail) y se desencadenen advertencias en los marketplaces.
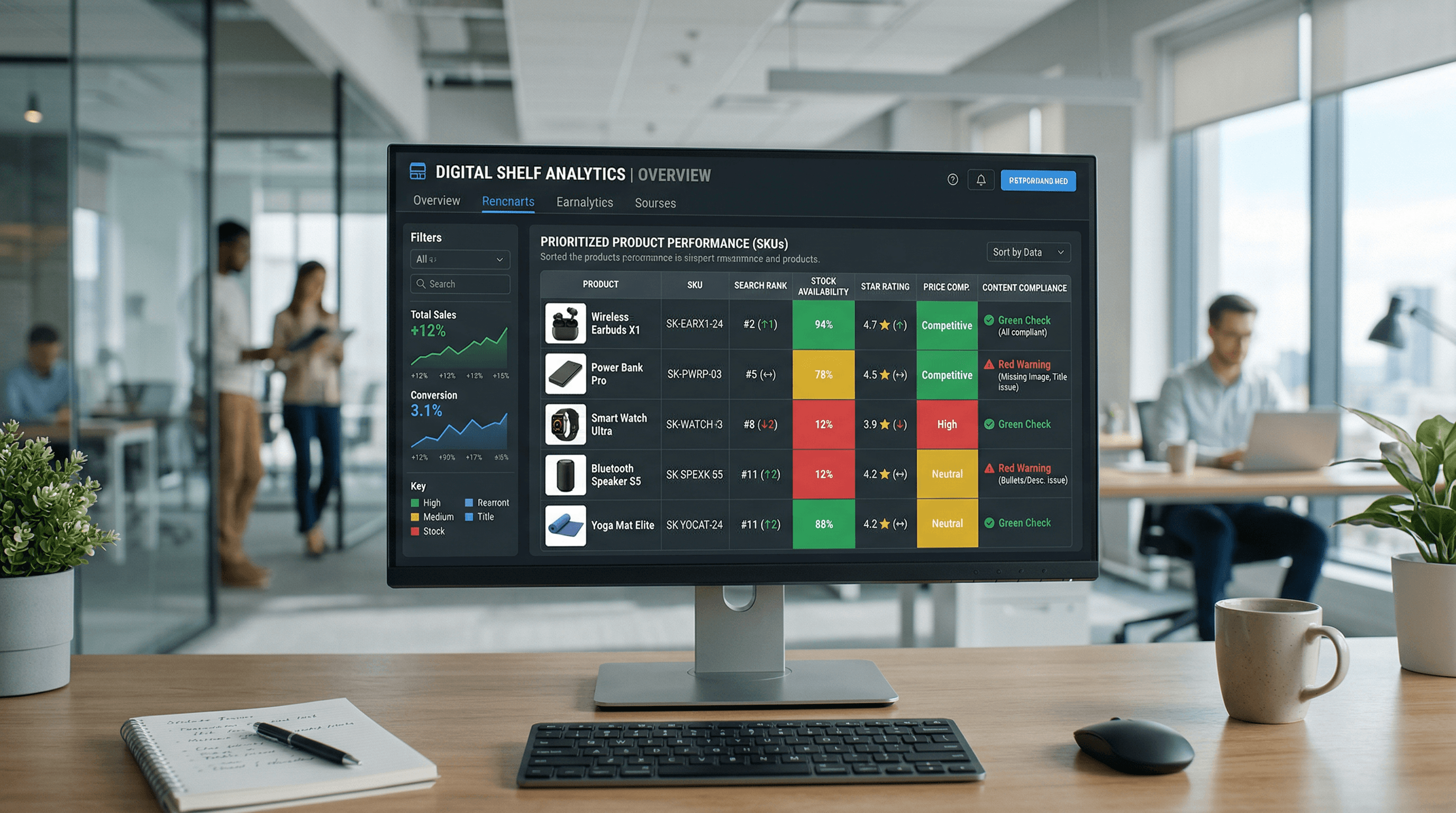
Dashboards y KPIs
Por qué es importante: Los dashboards (paneles de control) convierten las reglas estáticas en señales operativas accionables.
Haz un seguimiento de las tasas de acierto de las reglas, las tendencias de rechazo de feeds, la completitud de atributos por canal y el tiempo medio de resolución. Crea vistas desglosables (drillable) que enlacen directamente a los SKUs problemáticos. Si un dashboard señala que al 15% del inventario de la nueva temporada le faltan las imágenes principales, el catalog manager debería poder hacer clic para ver exactamente qué proveedor no subió los assets, reduciendo drásticamente el tiempo de investigación.
Utiliza herramientas de BI o monitorización casi en tiempo real en tu pipeline de feeds, e integra alertas en tu rastreador de incidencias para que cada infracción se convierta en un ticket rastreable.
Ejemplo: Un dashboard de KPIs muestra un pico repentino de rechazos en el marketplace para el atributo "Talla". El catalog manager filtra la vista para aislar tres proveedores específicos y abre tareas correctivas inmediatamente.
Error típico: Informar sobre métricas de vanidad (como el recuento total de SKUs) sin vincular la calidad de los datos con el impacto en el negocio (como pérdida de visibilidad o checkouts bloqueados). Para ver las mejores prácticas, revisa las directrices sobre cómo gestionar metafields de Shopify.
SLAs y checklist de triaje de incidencias
Por qué es importante: Los SLAs (Acuerdos de Nivel de Servicio) evitan que los pequeños problemas de mapeo se conviertan en fallos sistémicos del catálogo.
Define niveles de prioridad, asigna responsables y establece rutas de escalado en una matriz RACI que cubra las operaciones de catálogo, de proveedores y el desarrollo. Automatiza la asignación de responsables en función de la categoría o el feed de origen, y establece ventanas de tiempo claras para el reconocimiento y la resolución.
Checklist de triaje:
Reconocer los fallos críticos del feed en 1 hora.
Asignar el ticket a un responsable automáticamente en 2 horas.
Desplegar correcciones críticas en 24 horas; las no críticas en 5 días laborables.
Ejecutar un breve análisis de causa raíz para rechazos repetidos en 7 días.
Error típico: Depender del enrutamiento manual de correos a una bandeja de entrada compartida, lo que crea cuellos de botella y respuestas tardías.
IA segura para el enriquecimiento de contenido
Por qué es importante: La IA aumenta drásticamente el rendimiento para las descripciones de productos y la extracción de atributos, pero requiere salvaguardas estrictas para evitar que las alucinaciones lleguen a los listados en vivo.
Trata los resultados de la IA como sugerencias que deben ser etiquetadas, versionadas y puestas en staging. Aplica las mismas validaciones basadas en reglas que utilizas para la entrada humana —comprobando los valores permitidos, los patrones regex y las políticas del marketplace— antes de publicar. Guarda siempre los metadatos de procedencia (etiquetando los datos como generados por IA) y mantén una ruta clara de rollback.
Ejemplo: Un modelo de IA generativa completa los bullet points (viñetas) que faltan de una nueva línea de ropa, pero una regla de validación automática bloquea la subida porque la IA incluyó reclamos promocionales prohibidos ("Envío gratis") y declaraciones de precios.
Error típico: Publicar resultados de IA directamente en Shopify o Merchant Center sin seguimiento de procedencia ni validación, provocando inevitablemente rechazos en el feed y advertencias de cumplimiento.
Automatizar la gobernanza del catálogo con IA
Construir diccionarios, mapear metafields y aplicar procesos de QA manuales requiere mucho tiempo, lo que a menudo aleja a los equipos de las iniciativas reales de crecimiento. Cuando la gobernanza es puramente manual, la aplicación de reglas falla y los catálogos se degradan con el tiempo.
ButterflAI automatiza esta carga operativa por completo. En lugar de gestionar hojas de cálculo complejas y reglas de validación manuales, ButterflAI audita continuamente los datos de tus productos, mapeando instantáneamente los atributos, normalizando variantes y enriqueciendo los campos que faltan de forma segura. Aplica las mejores prácticas de gobernanza directamente dentro de tus ecosistemas Shopify y PIM, garantizando que tu catálogo se mantenga listo para cualquier canal, en total cumplimiento de sus normas y optimizado para ser descubierto.