Qué controla realmente robots.txt en Shopify (y qué no)
Robots.txt en Shopify marca la primera barrera para el rastreo de rutas por motores de búsqueda pero no determina por sí mismo qué páginas se indexan. Entender la diferencia entre rastreo e indexación y su relación con sitemap y rel canonical evita cambios que reduzcan la visibilidad de catálogos grandes.
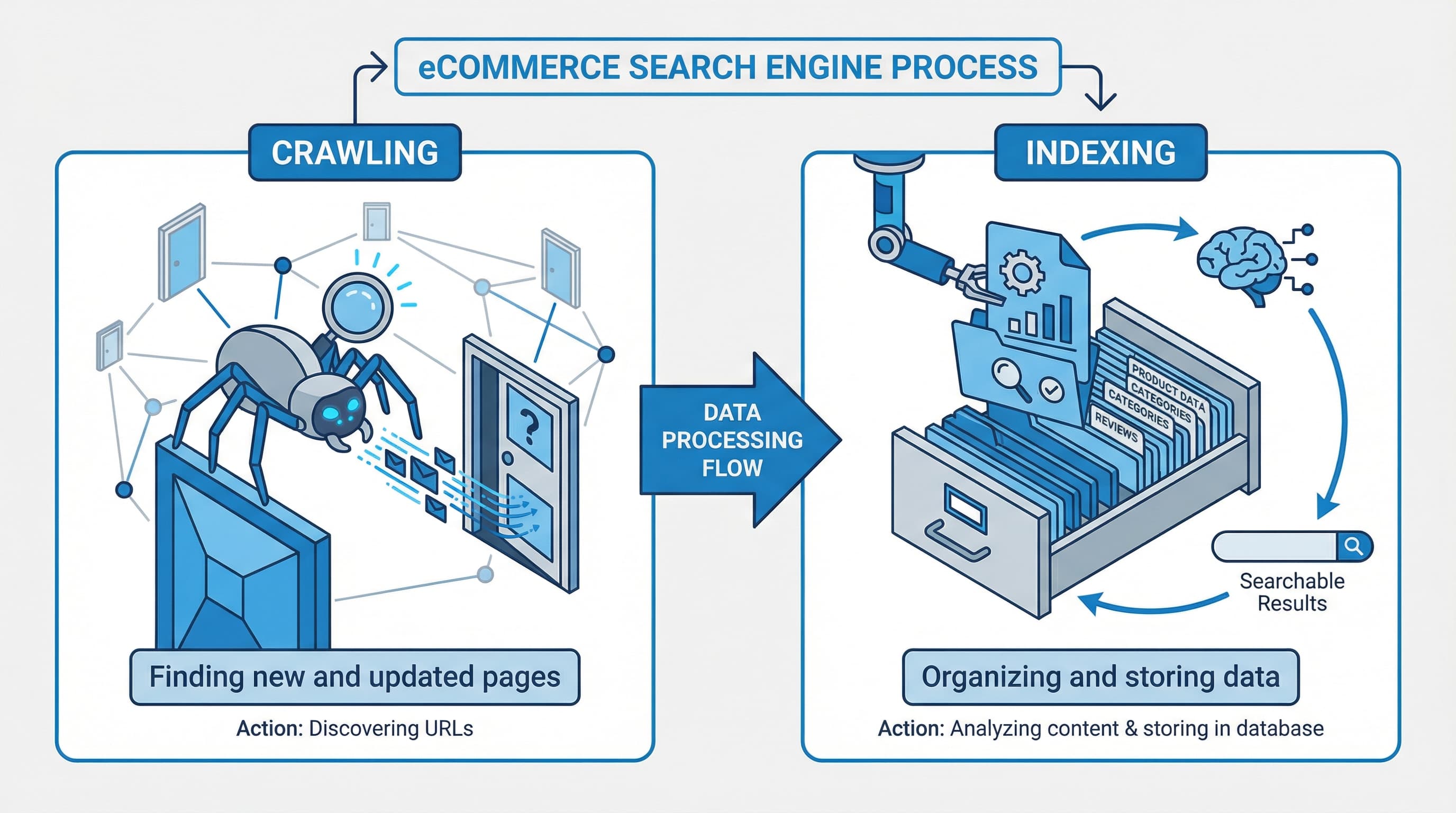
Diferencia entre rastreo e indexación
Contexto: El rastreo es la petición que hace un bot para recuperar una URL; la indexación es la decisión del buscador de almacenar y mostrar esa página.
Abordaje: Use robots.txt para limitar las rutas que pueden ser solicitadas por bots y use etiquetas noindex o rel canonical para controlar qué se incorpora al índice. Robots.txt impide que un bot descargue el contenido pero no impide que la URL sea conocida si existen enlaces externos. Para referencia técnica consulta la documentacion de Google search
Ejemplo breve: Una página bloqueada en robots.txt puede aparecer como URL conocida en Search Console aunque no esté indexada.
Error típico: Confundir bloquear con aplicar noindex y cerrar el acceso a archivos CSS o JavaScript necesarios para el renderizado.
Qué hace realmente robots.txt en Shopify
Contexto: robots.txt indica a los rastreadores si pueden solicitar una URL; Shopify sirve un robots.txt dinámico por defecto.
Abordaje: Utilice robots.txt para reducir el rastreo de endpoints administrativos, APIs públicas innecesarias y parámetros que generan variaciones triviales. No bloquee assets ni sitemaps que facilitan el renderizado y el descubrimiento. robots.txt.liquid es la plantilla del tema que permite personalizar reglas en tiendas que lo soportan y es crítica porque un error puede impedir que Google cargue recursos.
Ejemplo breve: Bloquear parámetros de filtrado reduce peticiones sobre colecciones manteniendo indexable la versión canonical del catálogo.
Error típico: Bloquear feeds o sitemaps por accidente y cortar el canal principal de descubrimiento.
Limitaciones nativas de Shopify y buenas prácticas
Contexto: No todas las tiendas permiten el mismo nivel de personalización y algunas reglas son gestionadas por la plataforma.
Abordaje: Si edita robots.txt.liquid pruebe cambios en un entorno de pruebas y valide con Search Console que no se bloqueen archivos JSON CSS ni endpoints usados por el storefront. Combine bloqueos selectivos con canonical y noindex para resolver duplicados y páginas de baja calidad.
Ejemplo breve: Una regla amplia que bloquee /assets/ impide la ejecución de scripts y degrada la evaluación de la página.
Error típico: Aplicar una plantilla genérica sin adaptar rutas del tema y romper el renderizado.
Validación con Search Console
Contexto: Validar evita que un cambio impacte la indexación sin aviso.
Abordaje: Use la inspección de URL y el informe de cobertura en Google search console para comprobar acceso e indexación. Tras actualizar robots.txt solicite reinspección de las URLs afectadas.
Ejemplo breve: Una URL marcada como bloqueada por robots.txt debería pasar a accesible tras actualizar el archivo y pedir reinspección.
Error típico: No solicitar reinspección y asumir que Google reevaluará de inmediato.
Conclusión
Robots.txt controla acceso al rastreo pero no la indexación final. En Shopify combine robots.txt sitemap y rel canonical para reducir crawl waste y proteger la visibilidad del catálogo.
Plantilla de robots.txt.liquid para eCommerce (segura)
Robots.txt en Shopify editarlo sin romper la indexación es una necesidad para tiendas con catálogos grandes que generan miles de combinaciones de facetas y rutas de búsqueda. Esta sección entrega una plantilla segura en Liquid, reglas prácticas para bloquear filtros y búsqueda interna, y pasos de validación con Search Console para reducir el crawl waste sin perder páginas importantes.
TLDR
- Bloquear solo rutas que generan duplicidad o paginación infinita
- No bloquear assets necesarios para renderizado
- Validar cada cambio en Search Console y logs de rastreo
Nota técnica breve
robots.txt.liquid es la plantilla que genera el archivo robots.txt en Shopify; sirve para personalizar reglas por tienda sin tocar la infraestructura del CDN. PIM es un sistema de gestion del catalogo centralizado; importa porque de el salen las URLs canonicas. sitemap.xml es el indice de URLs que ayuda a buscadores a priorizar el rastreo. rel canonical es la etiqueta HTML que indica la version preferida de una pagina y evita duplicidad.
Robots.txt en Shopify y reglas seguras
Shopify sirve un robots.txt por defecto pero permite editar robots.txt.liquid para ajustes avanzados. La regla de oro: bloquear solo lo que no aporta valor a la indexación principal y dejar accesibles los recursos de renderizado.
Qué bloquear para controlar facetas y filtros
Contexto
Las facetas y filtros producen combinaciones infinitas que inflan el catalogo y consumen presupuesto de rastreo.
Cómo abordarlo
Prioriza bloquear rutas identificables por patrones de query que nunca deben posicionar, como busquedas internas, filtros con ids y paginación de colecciones. Complementa con rel canonical en las plantillas de coleccion para apuntar a la version principal y meta noindex donde proceda.
Ejemplo
Disallow user-agent star Disallow /search Disallow /*q= Disallow /*filter= Disallow /*sort= Disallow /*page=
Error típico
Bloquear parametros sin comprobar canonical puede impedir indexar versiones validas que usan los mismos parametros.
Qué NO bloquear
Contexto
Google necesita recursos para renderizar y evaluar cada página; bloquearlos perjudica el posicionamiento.
Cómo abordarlo
No bloquees archivos css y js del tema, ni rutas de imagenes de producto, sitemap.xml ni las rutas principales de productos y colecciones que quieras indexar. Si tu PIM exporta un feed, asegúrate que la URL del feed y las rutas que contiene son accesibles.
Ejemplo
Allow /assets Allow /images Allow /sitemap.xml Allow /products Allow /collections
Error típico
Bloquear assets provoca que Search Console muestre problemas de renderizado y que Google no evalúe correctamente la pagina.
Plantilla técnica segura robots.txt.liquid
Contexto
A continuacion una plantilla lista para copiar en robots.txt.liquid y adaptar al prefijo de tu tienda.
Cómo abordarlo
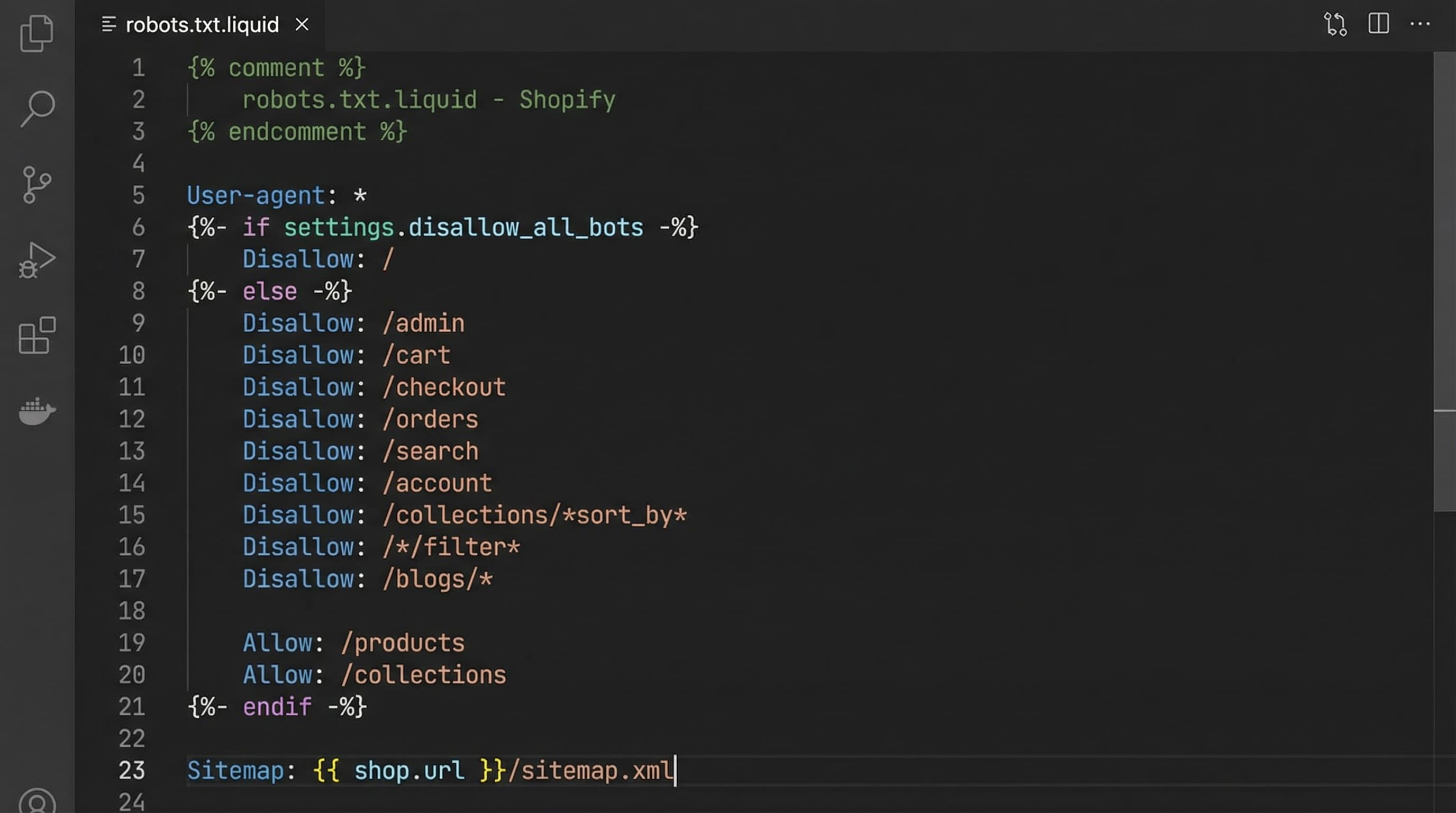
Copia la plantilla en un entorno de staging, ajusta patrones concretos del tema y documenta cada Disallow con un comentario. Mantén reglas conservadoras: mejor añadir patrones gradualmente y validar impacto.
Ejemplo de plantilla
User-agent: * Disallow: /search Disallow: /*q= Disallow: /*filter= Disallow: /*sort= Disallow: /*page= Allow: /products Allow: /collections Allow: /assets Allow: /sitemap.xml
Error típico
Pegar plantillas genericas sin reemplazar los patrones de tu tema puede bloquear rutas validas y feeds.
Validación con Search Console
Contexto
Verificar el robots tras editar evita sorpresas en cobertura e indexación.
Cómo abordarlo
Usa la herramienta de inspección de URL y la comprobación del archivo robots en Search Console para probar URLs concretas. Revisa el informe de cobertura y los logs de rastreo para detectar URLs que Google visitaba y ahora ignora. Si corriges reglas, solicita inspección publica de URLs prioritarias para acelerar la nueva evaluación.
Ejemplo
Probar la URL de un producto en Search Console y comprobar que no aparece bloqueada por robots ni presenta errores de renderizado.
Error típico
No solicitar una nueva inspección luego del cambio y asumir que Google aplico la nueva version.
Checklist rapido y buenas practicas
- Hacer backup del tema antes de editar robots.txt.liquid
- Probar cambios en staging y aplicarlos gradualmente en produccion
- Priorizar indexacion de productos y colecciones canonicas
- Usar rel canonical y meta noindex solo en paginas de baja calidad
- Monitorizar logs de rastreo y el informe de cobertura en Search Console
Fuentes
Guia de directivas de robots y mejores practicas
Como acceder y editar archivos de tema en Shopify
Implementación paso a paso en el editor de temas
Robots.txt en Shopify es la primera barrera para controlar lo que los motores de busqueda rastrean en un catalogo grande. En tiendas con muchas facetas y filtros, un robots.txt mal configurado incrementa el crawl waste y puede provocar indexacion de paginas de baja calidad o duplicadas. Esta guia paso a paso muestra como implementar cambios seguros en el editor de temas de Shopify y validarlos sin riesgos.
Robots.txt en Shopify paso rapido
Sigue este flujo minimo para aplicar cambios sin interrumpir indexacion: duplicar el tema, editar robots.txt.liquid en la copia, probar rutas concretas con Search Console y desplegar en produccion solo cuando los tests pasen.
Crear copia del tema
Por que importa
Un rollback rapido evita downtime y errores de indexacion tras cambios en el archivo de reglas.
Como abordarlo
En el panel de Shopify abre Online Store temas, duplica el tema activo y trabaja sobre la copia. Mantén un nombre claro con fecha y anota los cambios en el changelog del equipo.
Ejemplo breve
Duplicar tema y renombrar backup-robots-2026-01-15
Error tipico
Editar directamente el tema activo sin copia de seguridad
Editar archivo robots.txt.liquid
Por que importa
El archivo robots.txt.liquid permite personalizar reglas por tema y bloquear patrones de filtros sin editar cada URL.
Como abordarlo
Abrir editor de codigo del tema copia y localizar robots.txt.liquid. Añadir reglas Disallow para parametros tipicos de facetas y paginacion y conservar Allow para archivos estaticos y sitemap.xml. Usa patrones sencillos y evita bloques generales que incluyan rutas de productos o colecciones.
Ejemplo breve
User-agent: *
Disallow: /search
Disallow: /?q=
Disallow: /?sort=
Allow: /sitemap.xml
Error tipico
Bloquear /collections o /products, lo que impide indexacion de fichas validas
Nota tecnica
Shopify metafields son campos personalizados que almacenan datos adicionales de producto; importan porque alteran lo que se muestra en ficha y pueden generar variantes de contenido. PIM es el sistema que centraliza atributos del catalogo; importa para mantener consistencia. Feed es el fichero que exportas a marketplaces; controla que URLs se compartan.
Validar en Google Search Console
Por que importa
Validar evita lanzar reglas que bloqueen rastreo de contenido importante accidentalmente.
Como abordarlo
Usa la herramienta de prueba de robots en Google Search Console y la inspeccion de URL para comprobar rutas concretas. La documentacion oficial de Google sobre robots ayuda a entender la sintaxis y la guia de Shopify aporta notas practicas.
Ejemplo breve
Probar /search?q=zapatillas y /products/mi-sku para confirmar comportamiento
Error tipico
Confiar en simuladores externos sin comprobar la respuesta real desde Search Console
Validación y monitoreo con Search Console
Robots.txt en Shopify requiere validación y monitoreo para evitar bloqueos accidentales que reduzcan visibilidad y ventas. Robots.txt es un archivo que indica a los rastreadores qué rutas no deben visitar y ayuda a controlar el gasto de rastreo. Search Console es la herramienta de Google para comprobar indexación y errores técnicos y permite simular reglas. Sitemap es el listado de URLs que priorizas para indexación. Crawl budget es la cantidad de recursos que Google asigna para rastrear tu sitio, crítico en catálogos grandes.
Consulta la guía de Google para el probador de robots txt y la documentación de Shopify sobre robots.txt
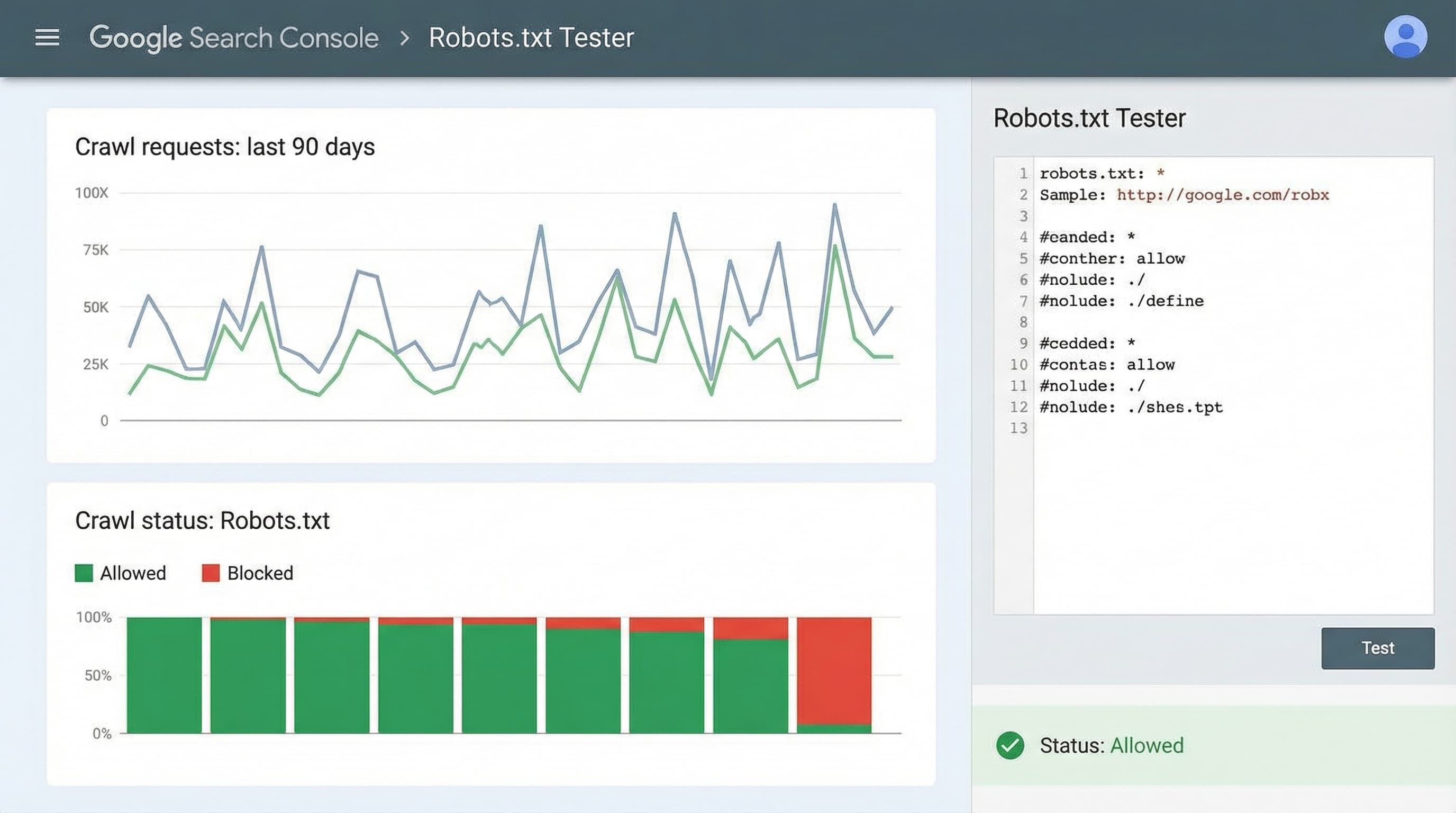
Robots.txt en Search Console probador y comprobaciones
Contexto por que importa este paso
El probador permite saber si una URL queda bloqueada por las reglas y con qué user agent ocurre.
Como abordarlo
Pegar la versión provisional de robots.txt en el probador y testear rutas representativas: home, una colección, un producto, feeds y URLs con parámetros de filtro. Complementar con Inspección de URL para verificar renderizado y razón de exclusión.
Ejemplo breve
Probar una URL de colección y una URL con varios filtros para confirmar que no estén bloqueadas.
Error típico
Comprobar solo la home y omitir rutas de catálogo con parámetros
Monitoreo del impacto en el rastreo y crawl budget
Contexto por que importa este paso
Un bloqueo bien planteado reduce crawl waste; un bloqueo erróneo puede dejar sin indexar páginas comerciales.
Como abordarlo
Comparar Crawl Stats y el informe de Cobertura antes y después del cambio. Filtrar por Paginas excluidas y la razón Blocked by robots txt. Mantener un registro de cambios con fechas y reglas aplicadas para facilitar la correlación con variaciones en rastreo e impresiones.
Ejemplo breve
Detectar caída de rastreo en páginas de categoría tras añadir una regla Disallow que afectó a un folder compartido.
Error típico
Tomar una bajada de rastreo como señal de penalización sin revisar robots.txt ni logs del servidor
Señales de alerta y pasos de recuperacion
Contexto por que importa este paso
Detectar rápidamente evita pérdida de visibilidad y posibles caídas de ingresos.
Como abordarlo
Vigilar aumentos de páginas excluidas por robots txt, errores de cobertura y caídas de impresiones en Search Console. Pasos de recuperación: revertir la regla sospechosa, usar Inspección de URL para solicitar indexación, reenviar sitemap y revisar logs de rastreo. Coordinar con producto para desplegar corrección urgente si hay muchas URLs afectadas.
Ejemplo breve
Revertir una línea Disallow que bloqueaba collections y solicitar reindexación.
Error típico
No correlacionar cambios en robots.txt con alertas en Search Console y actuar tarde
Calidad de contenido y optimización técnica
Optimizar el archivo robots.txt para controlar el rastreo es solo una pieza del puzzle. De nada sirve enviar a los bots a las páginas correctas si el contenido de esas páginas (títulos, descripciones, metafields) no está optimizado para convertir y posicionar. En catálogos extensos, la gestión manual de la calidad de los datos de producto es inviable. ButterflAI resuelve este desafío permitiendo a los equipos de eCommerce generar y optimizar contenido de producto a escala con IA, garantizando que cada URL que permites rastrear esté lista para competir en los resultados de búsqueda.