Qué es el FAQ Schema y por qué es importante
TL;DR: El FAQ schema son datos estructurados que ayudan a los motores de búsqueda a entender el contenido de preguntas y respuestas en las páginas de producto y pueden activar resultados enriquecidos que aumentan la visibilidad y el porcentaje de clics (CTR) orgánico para consultas de alta intención. Para la implementación técnica y los requisitos de políticas, consulta la guía de datos estructurados para FAQPage de Google.

El FAQ schema marca las preguntas de los clientes y las respuestas concisas y objetivas para que los motores de búsqueda puedan mostrarlas directamente en los resultados de búsqueda. Ese espacio extra a menudo mejora la visibilidad en las SERP y el CTR de las páginas de producto cuando las preguntas coinciden con la intención de compra. Una respuesta no promocional a una pregunta común previa a la compra puede evitar la pérdida de un clic y reducir drásticamente las devoluciones al establecer expectativas correctas directamente desde la página de resultados. Además, los datos estructurados influyen directamente en cómo los gráficos de conocimiento (knowledge graphs) de los motores de búsqueda y las nuevas funciones de búsqueda con IA generativa analizan los datos del producto.
Por qué es importante un enfoque basado en datos
Seleccionar preguntas por intuición desperdicia tiempo de contenido y desarrollo. También corre el riesgo de publicar respuestas promocionales o de bajo valor que los motores de búsqueda pueden degradar fácilmente. En su lugar, utiliza señales de origen como tickets de soporte, reseñas, motivos de devolución y registros de búsqueda del sitio web para encontrar consultas recurrentes de alta intención. Priorizar estas señales basadas en datos enfoca tus operaciones de contenido completamente en las preguntas que influyen directamente en las decisiones de compra y mejoran el CTR orgánico.
Flujo de trabajo centrado en la gobernanza
Es crucial definir reglas estrictas antes de un despliegue masivo para controlar la calidad y el cumplimiento. Los elementos clave de la gobernanza son los criterios de selección, los estándares de calidad, la propiedad (ownership) y un despliegue progresivo con marcos de medición claros.
Un ejemplo práctico de flujo de trabajo: selecciona un subconjunto piloto de productos, mapea preguntas canónicas con respuestas concisas y verificadas, almacena las preguntas y respuestas en un repositorio central, y expón el JSON-LD solo para los elementos aprobados. Este ritmo deliberado evita el uso excesivo del FAQ schema y mantiene tu marcado alineado con las directrices de calidad de los motores de búsqueda.
Conceptos técnicos básicos:
- Metafields de Shopify: Campos de producto personalizados para almacenar contenido estructurado por SKU, muy útiles para preparar datos de Q&A canónicos.
- PIM (Product Information Management): Un sistema central que gobierna y centraliza el contenido del catálogo en toda la organización.
- Feed: Una exportación de datos estructurados utilizada para enviar detalles del producto y campos de FAQ de forma segura a canales externos.
- Schema: El vocabulario estructurado (como JSON-LD) utilizado para marcar el contenido de forma que los motores de búsqueda puedan interpretarlo de manera fiable.
Obtención y mapeo del FAQ Schema
Comienza con un enfoque basado en datos para que tu FAQ schema refleje una intención de compra real, no suposiciones de marketing interno. Extrae preguntas de alta intención de tickets de soporte, registros de chat, reseñas de productos y motivos de devolución para apuntar a las consultas que influyen activamente en las tasas de conversión y la satisfacción poscompra.
Por qué es importante: Necesitas capturar las preguntas específicas que realmente causan fricción durante el proceso de compra.
Recopila hilos de correos electrónicos de soporte, transcripciones de chat en vivo, fragmentos de reseñas y notas de motivos de devolución. Exporta un periodo móvil, como los últimos 90 días, utilizando exportaciones CSV o APIs de tus herramientas de helpdesk. Normaliza el texto eliminando firmas de correo, marcas de tiempo y líneas de plantilla. Incluye siempre columnas de canal e ID de producto para que puedas mapear la frecuencia de consultas con precisión por SKU.
Ejemplo: Exporta columnas de canal, texto, ID de producto, fecha y etiqueta de ticket a una base de datos central para un análisis profundo.
Error común: Depender únicamente de tickets de soporte etiquetados manualmente, lo que garantiza que te perderás miles de preguntas críticas en texto libre enviadas por los usuarios.
Paso 2: Agrupar por intención y frecuencia
Por qué es importante: Agrupar el texto dinámicamente reduce la duplicación y destaca las intenciones de búsqueda de alto impacto.
Ejecuta una pasada basada en reglas para intenciones categóricas comunes como envíos, tallas, garantías y materiales. Luego, aplica agrupamiento semántico (clustering) o embeddings para fusionar preguntas parafraseadas a escala (por ejemplo, relacionar "¿es resistente al agua?" con "¿puedo usarlo en la lluvia?"). Etiqueta cada grupo con un identificador de intención y elige una pregunta corta y representativa que se pueda responder en una o dos oraciones. Prioriza los grupos por frecuencia e intención de compra inmediata para evitar incluir entradas de bajo valor.
Ejemplo: Fusionar "¿De qué tela está hecho?" y "¿Se encoge después de lavarlo?" en un único clúster de intención de materiales con una pregunta canónica sólida.
Error común: Publicar cada paráfrasis como una FAQ separada, lo que diluye severamente la autoridad de la página, crea contenido duplicado y genera una inmensa carga de mantenimiento.
Paso 3: Mapear a atributos del producto y establecer un flujo de aprobación
Por qué es importante: Las respuestas deben ser precisas por variante y legalmente seguras antes de que cualquier marcado estructurado se publique.
Mapea estos clústeres a los atributos exactos del producto que determinan la respuesta correcta, como la composición del material, las dimensiones, la duración de la garantía y la lógica de la política de devoluciones. Requiere que un Product Owner o redactor técnico escriba la respuesta canónica, y asegúrate de que un responsable de soporte o legal la apruebe oficialmente. Almacena las Q&A aprobadas en una tabla controlada o en un campo del PIM para que el despliegue en el front-end pueda automatizarse completamente y rastrearse fácilmente hasta el autor.
Ejemplo: Mapea un clúster de materiales directamente al metafield del producto material y completa la respuesta aprobada dinámicamente utilizando ese atributo específico.
Error común: Publicar respuestas genéricas no verificadas que varían incorrectamente según la variante del producto, lo que provoca reseñas negativas y problemas de cumplimiento normativo.
Ubicación: PDP vs. Centro de Ayuda
El FAQ schema debe estar fuertemente gobernado y provenir de señales reales de clientes para escalar de forma segura a través de miles de páginas de producto. Un flujo de trabajo centrado en la gobernanza convierte el feedback cualitativo de los usuarios en respuestas breves y objetivas que aparecen de forma visible en la Página de Detalle del Producto (PDP).
Alineación con la intención de la PDP
El contexto de la PDP es importante porque las páginas de producto son altamente transaccionales y requieren señales de compra inmediatas y concisas.
Mantén las FAQs de la página de producto estrictamente enfocadas en ajuste, compatibilidad, garantía, materiales y envíos para que las respuestas ayuden activamente a la conversión. Aborda esto mapeando cada pregunta con su intención de compra subyacente, y luego decide si la pregunta pertenece directamente a la PDP o se adapta mejor a un artículo extenso del Centro de Ayuda.
| Característica | Página de Detalle de Producto (PDP) | Centro de Ayuda |
|---|
| Objetivo principal | Eliminar bloqueos de compra inmediatos e impulsar la conversión (medido por la tasa de Añadir al carrito). | Resolver problemas poscompra o preguntas generales de la marca (medido por la desviación de tickets). |
| Formato del contenido | 1-2 oraciones concisas y objetivas que respondan la consulta exacta al instante. | Artículos detallados, guías paso a paso o tutoriales en video incrustados. |
| Intención de la pregunta | Específica para el SKU (ej., "¿Este cargador sirve para el modelo X?"). | Políticas generales de la marca (ej., "¿Cómo proceso una devolución internacional?"). |
Ejemplo de mapeo:
- Pregunta: ¿Por qué esta chaqueta viene pequeña?
- Respuesta: Se ajusta a la talla para la mayoría de clientes; elige una talla más si vas a usar capas de ropa.
- Error típico: Publicar respuestas de políticas largas y genéricas en la PDP que deberían enrutarse a artículos de soporte dedicados, empujando efectivamente el botón de Añadir al Carrito por debajo de la línea de pliegue (below the fold).
Gobernanza y seguridad
Una gobernanza estricta evita schemas engañosos o spam, lo que puede desencadenar fácilmente acciones manuales o penalizaciones por parte de los motores de búsqueda.
Requiere etiquetado de origen, propietarios de contenido dedicados y una cadencia de revisión obligatoria para cada entrada de FAQ. Registra siempre el origen exacto de los datos, como el ID específico del ticket de Zendesk o el ID de la reseña del producto.
Ejemplo de etiqueta de validación para seguimiento interno: Proof tag: Owner product team | Verified: 2026-01-15
Error típico: Inyectar respuestas en JSON-LD que hacen afirmaciones de marketing promocional agresivas que están completamente ausentes en el texto visible de la página.
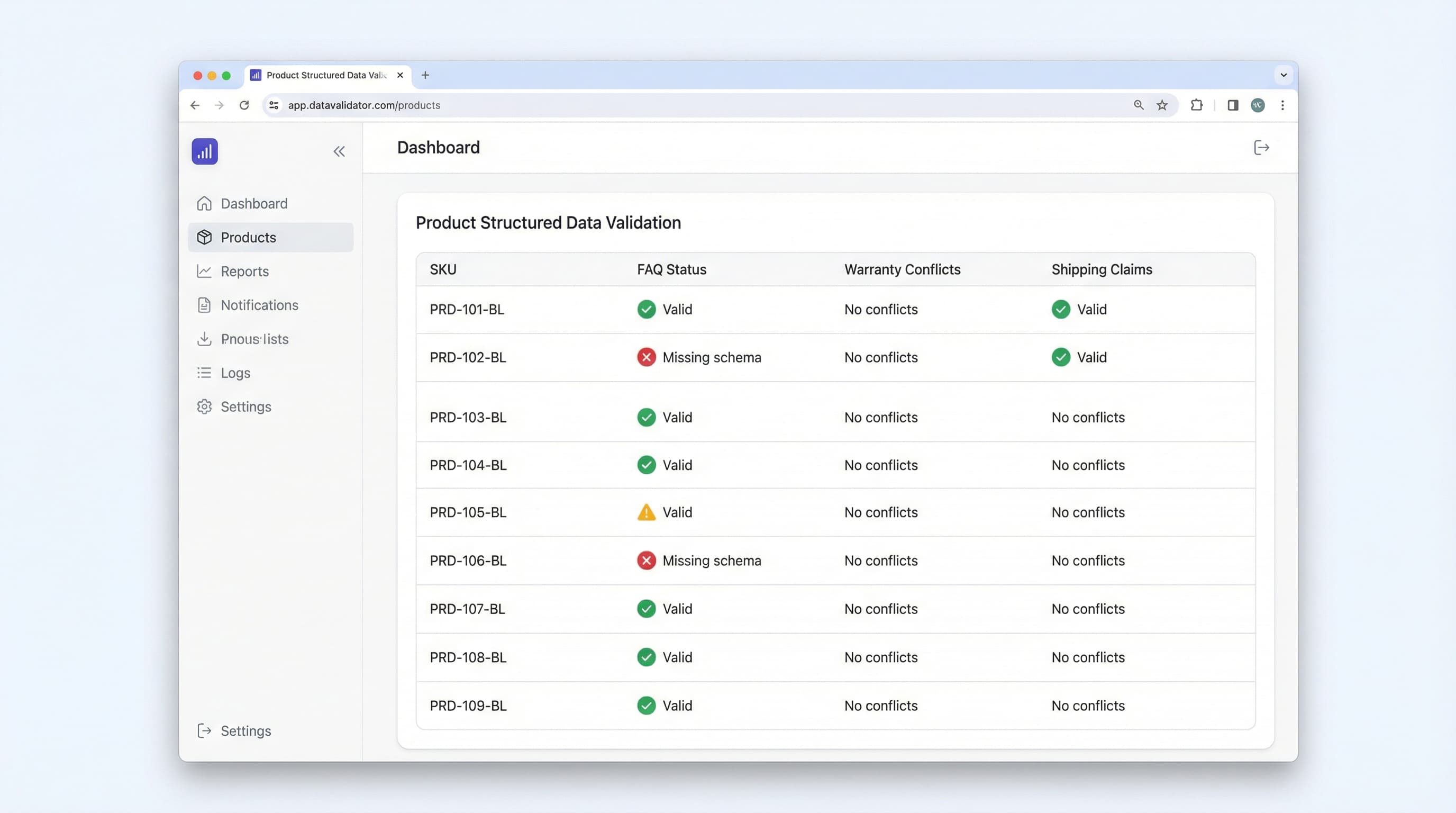
Ejecución técnica: Generadores y validación
Un FAQ schema compacto formateado específicamente para páginas de producto de ecommerce reduce la fricción de análisis (parsing) para los motores de búsqueda y maximiza la posibilidad de mostrar resultados enriquecidos orgánicos.
Estandarizar el payload de JSON-LD
Por qué es importante: Los datos estructurados consistentes ayudan a los motores de búsqueda a mostrar con confianza respuestas a nivel de producto en las SERP.
JSON-LD es el formato de datos estructurados preferido utilizado por los motores de búsqueda para mapear y entender el contenido de la página. Debes utilizar un patrón mínimo y seguro para producción, y completar las preguntas y respuestas anidadas exclusivamente con datos reales y validados de los clientes.
Estructura de plantilla de ejemplo:
@context: https://schema.org@type: FAQPagemainEntity:
@type: Questionname: ¿Este producto cuenta con envío internacional?acceptedAnswer:
@type: Answertext: Sí, enviamos a la mayoría de los países. Los tiempos de envío varían según el destino y se muestran en el checkout.
Error típico: Añadir respuestas promocionales, saturadas de palabras clave o excesivamente largas aumenta directamente el riesgo de eliminación completa de los resultados enriquecidos.
Uso de un generador a escala
Por qué es importante: La creación manual de miles de bloques individuales de FAQ JSON-LD es notablemente lenta, costosa y propensa a errores para catálogos empresariales.
Cómo abordarlo:
- Extrae preguntas de alta intención limpiamente de tickets de soporte, reseñas y motivos de devolución.
- Normaliza el texto sin procesar en oraciones simples y elimina sistemáticamente el lenguaje promocional no verificado.
- Mapea cada pregunta refinada a un ID de producto específico en tu PIM o sistema de mapeo de catálogos.
- Almacena las respuestas canónicas junto con un ID de origen único para asegurar pistas de auditoría estrictas.
- Renderiza el payload JSON-LD final por producto utilizando un motor de plantillas robusto, un microservicio dedicado o directamente durante el proceso de build de generación de sitios estáticos.
Validación y comprobaciones previas al despliegue
Por qué es importante: Los payloads JSON-LD mal formados pueden romper páginas, desencadenar acciones manuales de búsqueda o causar una pérdida repentina y catastrófica de resultados enriquecidos en todo el dominio.
Cómo validar:
- Consulta la Prueba de Resultados Enriquecidos de Google para verificar la elegibilidad técnica.
- Automatiza un control en el pipeline CI/CD (como GitHub Actions utilizando scripts de validación estándar como schema-dts en TypeScript) que valide explícitamente la sintaxis JSON, la presencia de campos y los límites de caracteres aceptables antes de fusionar el código (merge).
- Despliega inicialmente en una pequeña muestra de productos en staging y monitorea activamente Google Search Console en busca de advertencias de cobertura, picos de errores y cambios en el CTR.
Garantía de calidad (QA): Prevención de errores y datos obsoletos
Este marco de checklist proporciona a los equipos de QA y operaciones de contenido un flujo de trabajo robusto y estructurado para evitar respuestas duplicadas, corregir contradicciones de datos y eliminar sistemáticamente afirmaciones obsoletas mientras se preserva la integridad general del catálogo de productos. Esto es especialmente vital cuando se gestionan variantes en múltiples idiomas en configuraciones internacionales.
Prevenir respuestas duplicadas
Por qué es importante: Las respuestas duplicadas dividen las impresiones de búsqueda, confunden a los usuarios y diluyen agresivamente la autoridad general de la página.
Cómo abordarlo: Mantén un ID de respuesta canónica único dentro de tu PIM y haz referencia a él dinámicamente desde todas las entradas de FAQ a nivel de producto. Implementa reglas automatizadas de normalización y coincidencia semántica para fusionar continuamente los casi duplicados. Asegúrate de normalizar consistentemente tokens variables como duraciones, monedas locales, formatos de tallas y nombres de políticas para evitar falsos negativos durante la deduplicación automatizada.
Ejemplo: Dos variantes de color de hardware idénticas que comparten exactamente la misma política de devoluciones deben apuntar a un ID canónico para que las impresiones de búsqueda se consoliden de manera precisa.
Error típico: Publicar respuestas casi duplicadas en variantes que difieren solo en puntuación menor o frases insignificantes.
Corregir contradicciones entre variantes de producto
Por qué es importante: Las afirmaciones contradictorias aumentan drásticamente la carga de trabajo del centro de soporte y pueden desencadenar fácilmente comprobaciones de cumplimiento interno o problemas legales.
Cómo abordarlo: Compara sistemáticamente términos clave, duraciones y afirmaciones numéricas en familias de SKU estrechamente relacionadas. Ejecuta una detección activa de contradicciones utilizando comprobaciones basadas en reglas y embeddings semánticos para sacar a la luz conflictos inmediatos, enviando automáticamente los desajustes de alto impacto a una cola de triaje manual. Utiliza hipervínculos directos a fuentes de políticas autorizadas cuando resuelvas conflictos para mantener una pista de auditoría blindada.
Ejemplo: Marcar automáticamente los listados de escaparate activos que mencionen períodos de garantía contradictorios para artículos que operan dentro de la misma familia exacta de productos padre.
Error típico: Asumir que las reglas de herencia de datos de variantes funcionan perfectamente sin ejecutar una verificación real posterior a la publicación.
Actualizar afirmaciones obsoletas de envío y garantía
Por qué es importante: Las afirmaciones sensibles al tiempo afectan críticamente el cumplimiento legal, la confianza del comprador y el rendimiento general en las SERP.
Cómo abordarlo: Añade un campo estricto de metadatos de "última fecha de validación" y establece alertas automatizadas para cualquier artículo de FAQ con más de 90 días de antigüedad. Sincroniza estas respuestas de forma estrecha con tu feed logístico en vivo y utiliza metafields de Shopify para la ingestión de datos en tiempo real.
Ejemplo: Despublicar automáticamente cualquier respuesta del FAQ schema que haga referencia a promesas de entrega en días festivos obsoletas hasta que el equipo de operaciones logísticas las verifique manualmente de nuevo.
Error típico: Desplegar afirmaciones de entrega altamente sensibles al tiempo sin adjuntar un disparador asociado de "última fecha de validación".
Medición del impacto y mantenimiento de la actualización
Mantener la calidad del FAQ schema de forma inteligente evita la caída del CTR con el tiempo y minimiza significativamente el riesgo de generar fragmentos (snippets) de baja relevancia que frustran a los compradores.
Rendimiento del FAQ Schema en Search Console
Por qué es importante: Google Search Console es la fuente definitiva de la verdad para las impresiones del schema, los clics y los errores técnicos de resultados enriquecidos.
Cómo abordarlo: Navega al informe de Rendimiento y filtra activamente por página de destino o consulta específica para comparar un período de referencia histórico con el período activo actual. Exporta los datos en bruto a Google Sheets o BigQuery para un análisis agrupado detallado, trazando curvas de CTR frente a volúmenes de impresiones. Monitorea consistentemente el estado de tus resultados enriquecidos dentro del informe de Mejoras para detectar caídas de análisis de forma temprana.
Ejemplo: Filtra por una página de producto principal específica y compara directamente los 30 días antes y después de tu despliegue de FAQs para identificar los porcentajes exactos de aumento de CTR.
Error típico: Depender completamente de las métricas de CTR promedio de todo el sitio sin segmentar adecuadamente los datos por impresiones individuales por página.
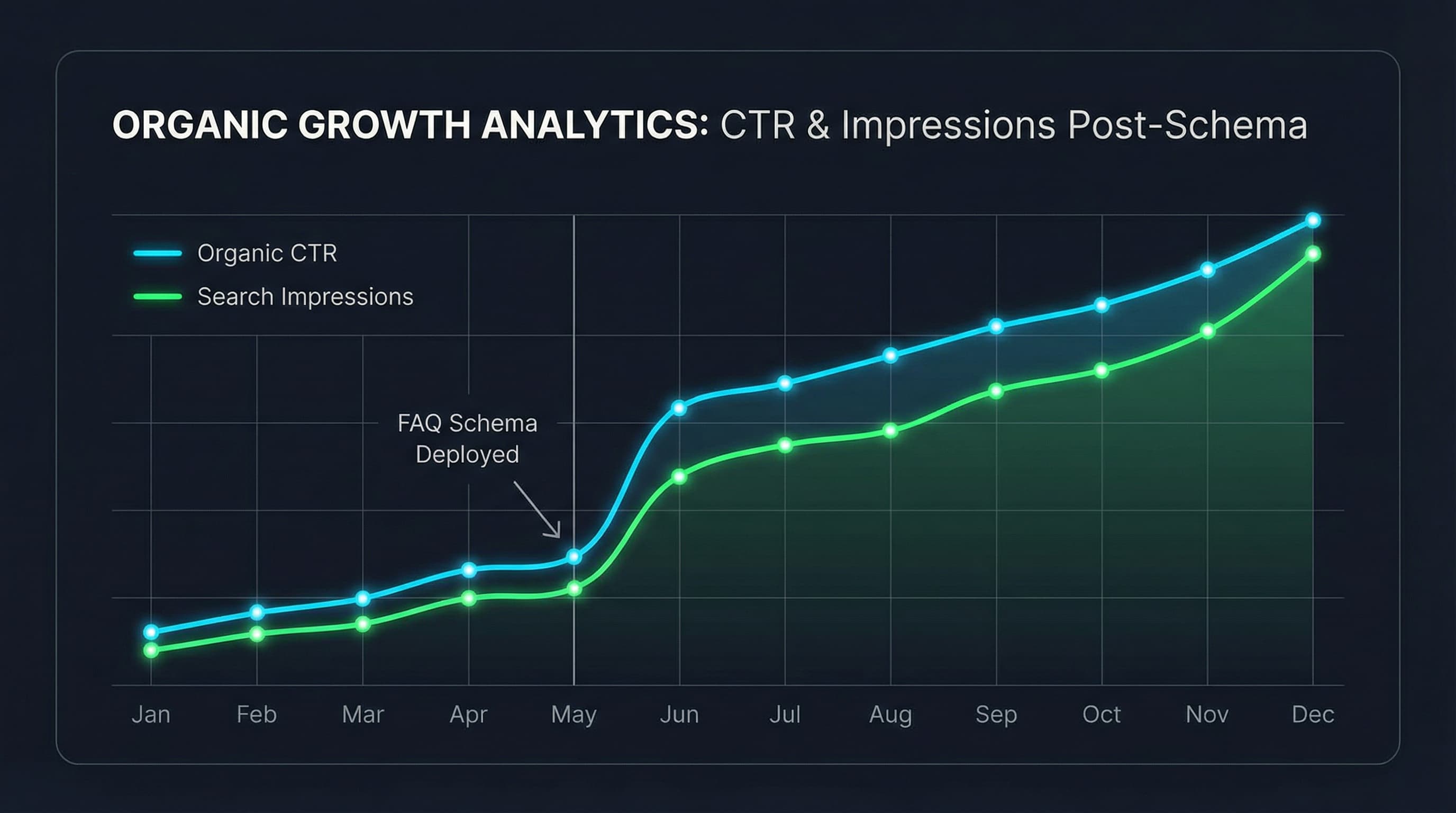
Proceso de actualización mensual
Por qué es importante: Las actualizaciones mensuales regulares garantizan que las respuestas publicadas sigan siendo profundamente relevantes para las preocupaciones actuales de los compradores y reducen drásticamente el contenido obsoleto o engañoso.
Ciclo de actualización paso a paso:
- Identifica las páginas de producto que generan activamente resultados enriquecidos de FAQ en los últimos 90 días, clasificándolas explícitamente por el total de impresiones de búsqueda.
- Elimina por completo el bloque visual de FAQ en la interfaz de usuario (UI) y el schema JSON-LD para cualquier SKU discontinuado, apuntando adecuadamente la URL canónica a las páginas de reemplazo activas.
- Extrae las principales preguntas nuevas de los clientes a partir de tickets de soporte, reseñas y devoluciones que cubran los 30 días anteriores.
- Redacta preguntas altamente concisas y orientadas a la intención junto con respuestas objetivas breves, validándolas estrictamente de forma directa con un experto técnico del producto (SME).
- Prueba el payload exhaustivamente en staging utilizando herramientas de prueba de datos estructurados, y ejecuta comprobaciones aleatorias in situ en el frontend en vivo.
- Despliega las actualizaciones por lotes geográficos o de categorías en fases, monitoreando Search Console de cerca en busca de cualquier error de datos estructurados recién introducido o cambios en el CTR.
Manejo de artículos descatalogados y medición del aumento de CTR:
Al manejar con éxito los artículos discontinuados, asegúrate de eliminar completamente la FAQ de la plantilla de la página, aplica una redirección 301 o un canonical a un reemplazo lógico, y verifica firmemente la eliminación dentro de la herramienta de inspección de URLs de Search Console. Para medir el impacto en el CTR de manera efectiva, agrupa tus páginas actualadas por impresiones, exporta los datos de rendimiento sin procesar y calcula sistemáticamente el aumento del CTR relativo antes y después del despliegue.
Error típico: No eliminar limpiamente el schema en SKUs inactivos, lo que causa una renderización de fragmentos irrelevantes en las SERP y una eventual caída del CTR en todo el dominio.
Automatización de la obtención y gobernanza del FAQ Schema
Extraer preguntas de alta intención de conjuntos masivos de datos no estructurados, agruparlas con precisión y desplegarlas en los metafields de producto correctos de forma manual es simplemente imposible de escalar en un catálogo de eCommerce grande. ButterflAI detecta puntos de fricción reales de los clientes a partir de tus datos de soporte y reseñas, automatizando completamente la creación, el mapeo y la gobernanza estricta del FAQ schema directamente en tu PIM o tienda Shopify. Para dejar de adivinar qué preguntan los compradores y escalar datos estructurados perfectamente formateados sin esfuerzo, explora ButterflAI.
Fuentes