Article video
Watch on YouTubeEcommerce Product List: A Playbook for High Conversions
Build a high-converting ecommerce product list with this step-by-step playbook. Learn data architecture, SEO, automation, and AI-driven workflows to scale.

Build a high-converting ecommerce product list with this step-by-step playbook. Learn data architecture, SEO, automation, and AI-driven workflows to scale.
Article video
Watch on YouTube
Master product feed management with this actionable guide. Learn to optimize workflows, improve data quality, and automate feeds for Google Shopping and beyond.
May 25, 2026

Master product catalog management software. This guide covers core features, benefits, buyer's criteria, and AI integration for better SEO and sales in 2026.
May 16, 2026
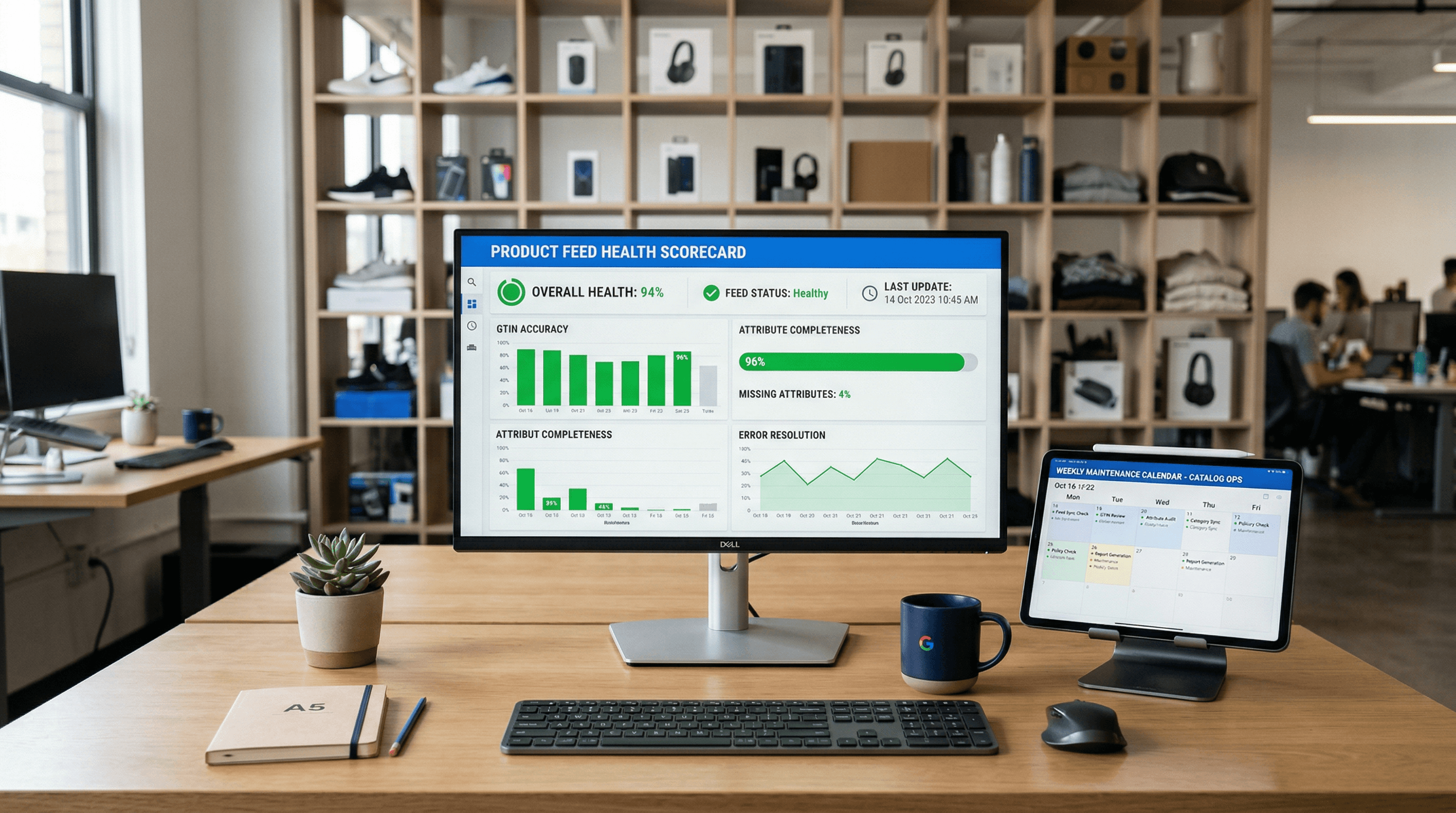
A practical QA scorecard and weekly workflow to prevent Merchant Center disapprovals, optimize your product data, and scale catalog growth.
Mar 4, 2026
Most advice about an ecommerce product list is too shallow. It tells teams to add more SKUs, write better titles, or upload cleaner images. Those things matter, but they don't fix the core problem. A large catalog without a strong taxonomy, complete attributes, and usable filters doesn't improve discovery. It makes discovery harder.
That trade-off matters more now because ecommerce is operating at massive scale. Global ecommerce sales are projected to reach $7.5 trillion in 2025, up from $5.7 trillion in 2023, and smartphones accounted for nearly 80% of all retail website visits worldwide in 2024, which raises the bar for mobile product list usability and structure according to Elementor's ecommerce statistics roundup. In that environment, the product grid isn't a gallery. It's your primary discovery engine.
A good ecommerce product list helps shoppers narrow options fast, understand variants before they click, and compare products with confidence. A bad one floods the page with inventory and asks the customer to do the work. The difference usually comes down to architecture, not copy.
Treat the product list like an operating system for findability. The content layer sits on top, but the engine underneath is data quality, taxonomy, filter logic, sort logic, and publishing discipline. Teams that get those pieces right can scale catalogs without turning their storefront into a maze.
The popular advice says bigger catalogs win. In practice, bigger catalogs often lose when teams don't control list architecture.
Baymard's research on major ecommerce sites found that users rely heavily on filtering and sorting by price, rating, and best-selling status, and that adding more products without strong filtering can make discovery worse, as summarized in Baymard's ecommerce UX best practices. That matches what operations teams see every day. A category with broad assortment and weak filters produces more browsing, more backtracking, and lower confidence.
More inventory only helps when shoppers can reduce it quickly.
The strongest ecommerce product lists do three jobs at once. They expose the catalog to search systems. They guide shoppers to the right subset of products. They prepare the customer for a higher-quality click into the product page.
That means the list itself has to carry real informational weight. It needs a clean category structure, complete attributes, sensible variant handling, availability visibility, and sort options that reflect buying behavior. It also needs workflows that keep those elements accurate when the catalog changes.
A scalable playbook starts with the data model, not the design mockup. If the underlying product records are inconsistent, the filters won't work cleanly, automated content will be noisy, and merchandising decisions will become manual patchwork. If the underlying product records are structured properly, the list becomes something much more useful than a grid. It becomes a dynamic discovery layer that can grow with the business.
Most product list problems start upstream. Teams blame design, SEO, or conversion copy when the underlying issue is incomplete product data.
An ecommerce product list can only be as good as the records feeding it. If one T-shirt has color, material, sleeve length, and stock status while another only has a title and image, the category page will feel inconsistent no matter how polished the front end looks.

Every SKU should enter the catalog with a mandatory field set. The exact schema varies by category, but the operating principle doesn't.
Use this as a baseline:
If that sounds closer to a PIM spec than a content brief, that's because it is. Content quality depends on structured source data. Without that, the team will keep writing around missing facts.
A useful reference point is this guide to product catalog management software, especially for teams moving from spreadsheet-based workflows to a centralized catalog process.
Data structure alone won't save you if no one owns field quality. The fix is governance with simple rules.
Create a working standard for each field:
| Field area | Rule to enforce | Why it matters on the list |
|---|---|---|
| Category | One approved taxonomy path per product | Prevents duplicate placement and messy filtering |
| Color | Controlled vocabulary | Stops "navy", "dark blue", and "midnight" from fragmenting filters |
| Size | Standardized format by category | Keeps variant comparison usable |
| Material | Approved values and order | Supports filter consistency and SEO clarity |
| Availability | Synced from inventory source | Prevents misleading clicks |
Practical rule: If a field drives filtering, sorting, variant logic, or list copy, don't allow free-text entry without validation.
Operationally, teams should audit for completeness and consistency before they optimize the storefront. Look for null values, duplicate attribute labels, mixed measurement formats, broken parent-child relationships, and products sitting in catch-all categories. Those issues don't stay in the database. They surface as confusing category pages.
Importify's guide to product selection adds another useful operational layer: evaluate each SKU by recent order velocity, total landed cost, competitive retail price, seasonality, and search demand, then launch only 3–5 products for an initial market test, with recurring keep/drop reviews to avoid overexpanding too early, as outlined in Importify's product selection workflow.
That logic applies to the product list itself. Don't publish assortment breadth you can't maintain with data discipline.
The biggest conversion lever on a list page usually isn't the headline or card design. It's whether the shopper can cut through the catalog without friction.

Internal merchandising logic often produces weak taxonomy. Teams organize around supplier lines, internal departments, or legacy menu structures. Shoppers don't think that way. They think in use cases, constraints, preferences, and comparison factors.
A strong taxonomy answers practical questions:
That means category trees should be narrow enough to be meaningful and broad enough to avoid dead-end fragmentation. "Skincare" might branch into cleansers, serums, moisturizers, and sunscreen. "Office chairs" might branch by ergonomic type, material, or intended setting if that reflects real buyer behavior.
Attribute design should support the same decision flow. For apparel, size and color are obvious. For electronics, compatibility and capacity often matter sooner. For supplements, format and key ingredients may matter before flavor. The right model depends on category intent.
A related merchandising payoff appears after shoppers find the right subset. Teams can then layer related-product logic more intelligently. For example, once taxonomy and attributes are stable, it's easier to boost average order value with FBT because product relationships are based on real compatibility and use context instead of loose manual tagging.
Not every attribute should become a filter. Too many filters create noise. Too few create browsing fatigue.
Start with attributes that materially change product choice. Baymard notes that users rely on clear filters and sorts such as price, rating, best-selling, and newest in large assortments, which is one reason filter architecture deserves priority over cosmetic list tweaks.
Use a simple decision screen:
Then separate attributes into roles:
| Attribute role | Examples | Use on list |
|---|---|---|
| Essential filters | Price, brand, size, color | Sidebar or top filter controls |
| Secondary filters | Material, feature set, fit, finish | Exposed after essentials |
| Card attributes | Rating, stock status, key variant cue | Visible before click |
| Detail-only attributes | Care instructions, warranty terms | Keep for PDP unless category demands otherwise |
One practical resource for this kind of field planning is this guide to product attributes, Shopify metafields, and SEO structure.
If the customer needs an attribute to compare products quickly, expose it before the click. If they only need it to validate a final choice, keep it deeper.
The strongest taxonomy work also reduces content debt. Once category paths and approved attributes are stable, you can automate titles, facets, collection copy, and internal search logic with much less cleanup.
Often, product copy is over-optimized, while product clarity is under-optimized. Search visibility matters, but list content has to help a shopper decide whether a click is worth it.

On a product list, the title is not a miniature ad. It's a compressed identifier. The best titles tell shoppers what the item is, what distinguishes it, and which variant cue matters most.
Nielsen Norman Group notes that users need clear explanations of product variations and availability directly on list items so they don't discover out-of-stock options only after clicking, as discussed in NN/g's guidance on ecommerce product pages. That has a direct writing implication. Titles and supporting list text should reduce uncertainty early.
A practical title formula often looks like this:
[Brand] + [Product Type] + [Key differentiator] + [Variant cue if essential]
Examples:
Avoid stuffing titles with every searchable term. That usually makes scanning worse. Put the decisive information first. Save secondary specs for bullet snippets or badges on the card.
Descriptions on list views should also stay functional. Good short descriptions answer one or two high-value questions:
The scaling problem isn't writing one strong listing. It's keeping thousands of listings distinct, accurate, and consistent.
Use templates, but don't rely on empty fill-in-the-blank language. Build modular copy blocks from approved attributes. If the product record includes material, fit, capacity, compatibility, and stock state, the system can assemble useful summaries without inventing claims.
A practical workflow looks like this:
A useful operational reference for title structure is this article on how to optimize product titles for SEO.
Thin list copy creates extra clicks. Clear list copy creates qualified clicks.
That distinction matters because the list page is increasingly part of the decision process, not just a path to the product page. AI-assisted discovery, richer search results, and marketplace-style browsing all reward structured and attribute-complete content. The teams that scale cleanly are the ones turning raw product data into readable list signals, not just publishing text in bulk.
Manual catalog operations break first at handoff points. Supplier sheet to merchandiser. Merchandiser to content team. Content team to ecommerce manager. Ecommerce manager to storefront. Every handoff creates lag, inconsistency, and rework.
An automated ecommerce product list pipeline reduces those handoffs by making the data model, content rules, and publishing flow work from the same source.
Start with the process view.

A workable pipeline usually has six stages:
Ingest Supplier feeds, ERP exports, marketplace imports, or platform-native catalog data enter a central source.
Validate Required fields are checked. Invalid category mappings, missing attributes, and inconsistent values are flagged before publication.
Normalize Units, attribute names, capitalization, variant relationships, and controlled vocabularies are standardized.
Generate Titles, short descriptions, metadata, image alt text, and category-facing snippets are created from templates or AI workflows.
Approve Review queues catch exceptions. Regulated categories, premium products, and sparse-data products get human review.
Publish Approved records sync to the storefront, search index, feeds, and channel-specific outputs.
The technical stack can vary. Some teams use a PIM plus Shopify. Others run ERP to middleware to WooCommerce. The architecture matters less than the control points. You need one source of truth, one validation layer, and one repeatable publishing workflow.
An AI content layer can serve this purpose. For example, ButterflAI's product feed management workflow is relevant for teams that want to map catalog fields, generate content in bulk, and push reviewed updates back into commerce platforms without rewriting every listing manually.
The operational model is easier to grasp when you watch it in motion:
Automation fails when teams automate chaos. It works when they automate decisions that already have clear rules.
Examples of rules worth encoding:
Then define where humans stay in the loop:
| Workflow area | Automate | Review manually |
|---|---|---|
| Attribute mapping | Common value normalization | New attribute creation |
| Title generation | Rule-based assembly | Ambiguous or premium products |
| Description generation | Repetitive category patterns | Compliance-sensitive claims |
| Publishing | Approved product sync | First-time category launches |
| Refreshes | Trigger-based updates |
| Strategic assortment changes |
Automation should remove repetitive catalog labor, not remove judgment.
A well-run pipeline also creates feedback loops. If customers repeatedly use a filter that returns weak results, taxonomy may need revision. If products with complete attribute cards get stronger engagement, the template should spread to similar categories. If out-of-stock variants are still causing frustration, availability logic needs to move earlier in the list experience.
Teams that treat product-list automation as a content task usually stall. Teams that treat it as an operational system usually scale.
A product list isn't finished when it goes live. It starts producing signals. The team's job is to read those signals correctly.
For ecommerce performance measurement, NetSuite reports an average ecommerce sales conversion rate of about 2%–3%, and Salesforce emphasizes add-to-cart rate and cart abandonment as core diagnostic metrics in Salesforce's commerce metrics guide. The useful lesson isn't the benchmark alone. It's that a weak outcome on one metric rarely has one cause.
If a category gets strong add-to-cart behavior but weak completed orders, don't rush to rewrite all product cards. The friction may sit in pricing perception, shipping surprises, or mismatch between list expectations and the product detail page. If conversion is low and list engagement is also low, then list architecture may be the primary issue.
Use a diagnostic matrix:
| Pattern | Likely issue | First action |
|---|---|---|
| High list engagement, low PDP click quality | Weak list clarity | Improve card attributes, titles, and variant cues |
| High add-to-cart, high abandonment | Checkout, shipping, or pricing friction | Audit thresholds, fees, and delivery messaging |
| Low filter usage in broad categories | Poor taxonomy or weak filter relevance | Rework filter set and category mapping |
| Strong PDP engagement, weak category discovery | List ranking issue | Adjust sort defaults and collection logic |
Most catalogs accumulate dead weight because no one defines what triggers a refresh versus a delist.
A clean operating routine uses recurring reviews with simple decision buckets:
Refreshes should be triggered by concrete symptoms, not gut feel. Common triggers include repeated customer confusion in reviews or Q&A, missing competitive attributes on the list card, poor variant communication, and stale category placement after assortment changes.
Testing should stay close to the list layer. Useful experiments include:
A lot of teams test headlines and banners while leaving filter logic untouched. That's usually the wrong priority. The list wins when shoppers can narrow the field with less effort and fewer surprises.
A modern ecommerce product list isn't a static collection page. It's a discovery system built from structured data, customer-oriented taxonomy, useful attributes, and disciplined publishing workflows.
That shift changes how teams should operate. Instead of asking whether the title sounds better or whether the grid needs one more badge, ask whether the product record is complete, whether the category path matches shopper intent, whether the filters reduce effort, and whether the publishing pipeline can keep quality consistent as the catalog grows.
The front end still matters. Titles, descriptions, images, and card design all influence clicks. But those outputs only work reliably when the underlying architecture is stable. That's why the strongest catalogs don't treat product-list optimization as a copy task. They treat it as a cross-functional operating model shared by ecommerce, merchandising, SEO, and catalog operations.
The payoff is bigger than cleaner category pages. A well-structured list improves findability, supports mobile browsing, strengthens search visibility, and prepares the catalog for AI-assisted discovery. It also makes the business easier to run because product launches, updates, and assortment decisions become more systematic.
Build the data model first. Design the taxonomy around real buying decisions. Expose the attributes that reduce uncertainty. Automate what can be standardized. Review what still needs judgment. That's how a product grid becomes a growth engine.
If your team is trying to scale catalog content without losing control of titles, descriptions, attributes, and publishing workflows, ButterflAI is built for that operational layer. It helps ecommerce teams turn structured product data into optimized product, SEO, blog, and AI-search content, with workflows that support bulk generation, review, and platform publishing.