What is FAQ Schema and Why It Matters
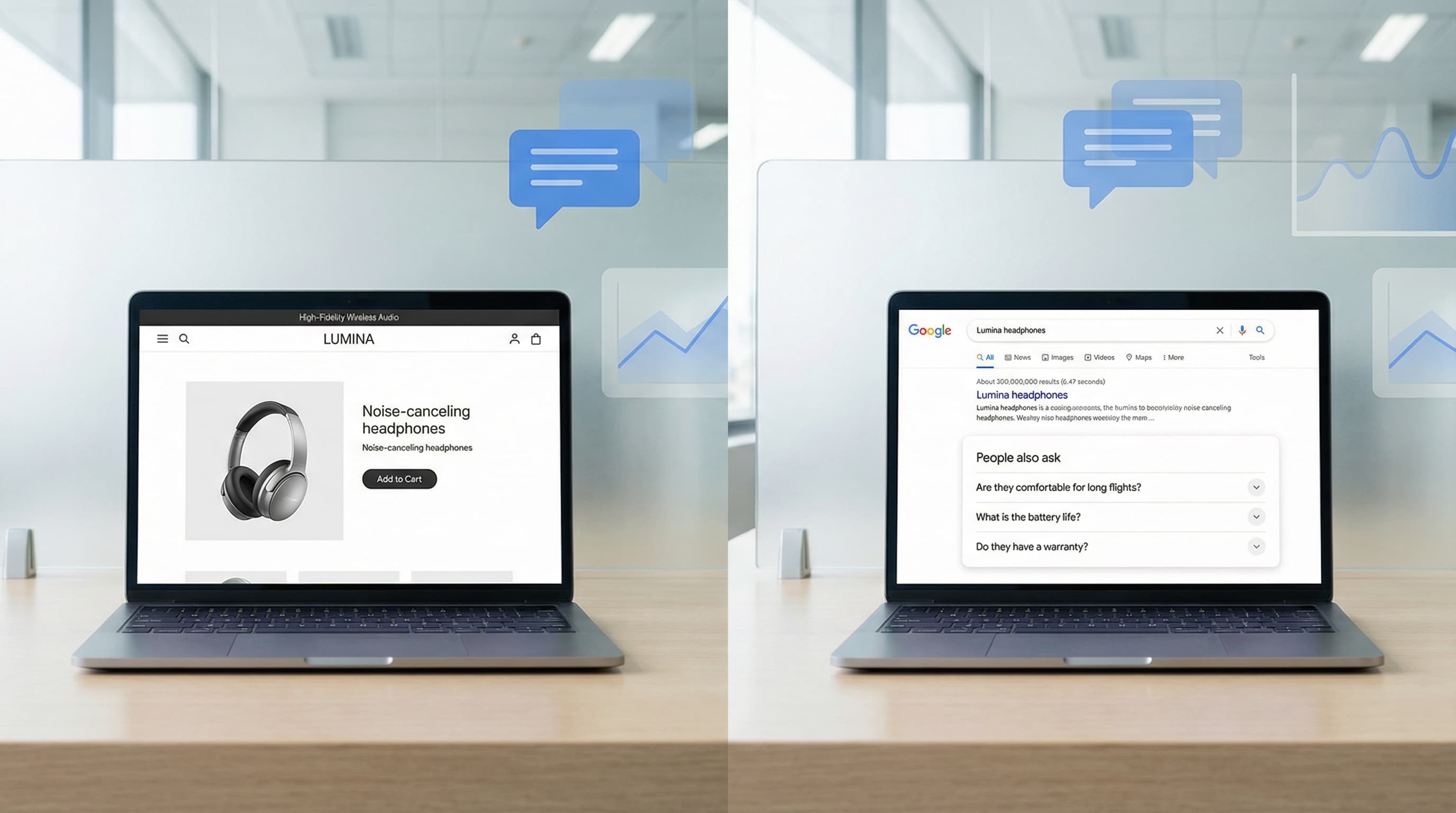
TL;DR: FAQ schema is structured data that helps search engines understand question-and-answer content on product pages and can enable rich results that increase visibility and organic click-through rate (CTR) for high-intent product queries. For technical implementation and policy requirements, refer to the Google FAQPage structured data guidance.

FAQ schema marks up customer questions and concise, factual answers so search engines can surface them directly in search results. That extra real estate often improves SERP visibility and CTR for product pages when the questions match buyer intent. A non-promotional answer to a common pre-purchase question can prevent a lost click and drastically reduce returns by setting correct expectations right from the search engine results page. Furthermore, structured data directly influences how product data is parsed by search engine knowledge graphs and emerging generative AI search features.
Why a Data-Driven Approach Matters
Selecting questions by guesswork wastes content and engineering time. It also risks publishing low-value or promotional answers that can easily be demoted by search engines. Instead, use source signals from support tickets, reviews, return reasons, and on-site search logs to find recurring, high-intent queries. Prioritizing these data-driven signals focuses your content operations entirely on the questions that directly influence purchase decisions and improve organic CTR.
Governance-First Workflow
It is crucial to define strict rules before mass deployment to control quality and compliance. Key governance items are selection criteria, quality standards, ownership, and staged rollout with clear measurement frameworks.
A practical workflow sample: pick a pilot subset of products, map canonical questions to concise verified answers, store the Q&A in a central repository, and expose JSON-LD only for approved items. This deliberate pacing prevents the overuse of FAQ schema and keeps your markup aligned with search engine quality guidelines.
Core Technical Concepts:
- Shopify metafields: Custom product fields for storing structured content per SKU, highly useful for staging canonical Q&A data.
- PIM (Product Information Management): A central system that governs and centralizes catalog content across the organization.
- Feed: A structured data export used to push product details and FAQ fields securely to external channels.
- Schema: The structured vocabulary (like JSON-LD) used to mark up content so search engines can interpret it reliably.
Actionable Checklist to Scale Safely
Sourcing and Mapping FAQ Schema
Start with a data-first approach so your FAQ schema reflects real purchase intent, not internal marketing assumptions. Extract high-intent questions from support tickets, chat logs, product reviews, and return reasons to target the queries that actively influence conversion rates and post-purchase satisfaction.
Step 1: Source Questions from Primary Channels
Why this matters: You need to capture the specific questions that actually cause friction during the buying process.
Collect support email threads, live chat transcripts, review snippets, and return reason notes. Export a rolling window, such as the last 90 days, using CSV exports or APIs from your helpdesk tools. Normalize the text by stripping out email signatures, timestamps, and template lines. Always include channel and product ID columns so you can map query frequency accurately by SKU.
Example: Export columns for channel, text, product ID, date, and ticket tag into a central database for deep analysis.
Common Error: Relying only on manually tagged support tickets, which guarantees you will miss thousands of critical free-text questions submitted by users.
Step 2: Cluster by Intent and Frequency
Why this matters: Grouping text dynamically reduces duplication and highlights high-impact search intents.
Run a rule-based pass for common categorical intents like shipping, sizing, warranty, and materials. Then, apply semantic clustering or embeddings to merge paraphrased questions at scale (e.g., matching "is it waterproof" with "can I use it in the rain"). Tag each cluster with an intent label and pick a short, representative question that is answerable in one or two sentences. Prioritize clusters by frequency and immediate purchase intent to avoid populating low-value entries.
Example: Merge "What is the fabric made of?" and "Does this shrink after wash?" into a single materials intent cluster with one strong canonical question.
Common Error: Publishing every single paraphrase as a separate FAQ, which severely dilutes page authority, creates duplicate content, and causes immense maintenance overhead.
Step 3: Map to Product Attributes and Set an Approval Workflow
Why this matters: Answers must be accurate per variant and legally safe before any structured markup goes live.
Map these clusters to the exact product attributes that determine the correct answer, such as material composition, dimensions, warranty duration, and return policy logic. Require a product owner or technical writer to author the canonical answer, and ensure a support or legal lead officially signs off. Store approved Q&A in a controlled table or PIM field so deployment to the front-end can be fully automated and easily traced back to the author.
Example: Map a materials cluster directly to the product metafield material and populate the approved answer dynamically utilizing that specific attribute.
Common Error: Publishing generic, unverified answers that incorrectly vary by product variant, leading to negative reviews and compliance issues.
PDP versus Help Center Placement
FAQ schema must be heavily governed and sourced from real customer signals to scale safely across thousands of product pages. A governance-first workflow turns qualitative user feedback into short, factual answers that appear visibly on the Product Detail Page (PDP).
Aligning with PDP Intent
PDP context matters because product pages are highly transactional and require concise, immediate buying signals.
Keep product page FAQs strictly focused on fit, compatibility, warranty, materials, and shipping so the answers actively help conversion. Approach this by mapping each question to its underlying purchase intent, then decide whether the question belongs directly on the PDP or is better suited for a long-form Help Center article.
| Feature | Product Detail Page (PDP) | Help Center |
|---|
| Primary Goal | Remove immediate buying blockers and drive conversion (measured by Add to Cart rate). | Solve post-purchase issues or broad brand questions (measured by ticket deflection). |
| Content Format | 1-2 concise, factual sentences answering the exact query instantly. | Detailed articles, step-by-step guides, or embedded video tutorials. |
| Question Intent | Specific to the SKU (e.g., "Does this charger fit the X model?"). | General brand policies (e.g., "How do I process an international return?"). |
Example mapping:
- Question: Why does this jacket run small?
- Answer: Fits true to size for most customers; size up for layering.
- Typical Error: Publishing long, generic policy answers on the PDP that should be routed to dedicated support articles, effectively pushing the Add to Cart button below the fold.
Governance and Safety
Strict governance prevents spammy or misleading schema, which can easily trigger manual actions or penalties from search engines.
Require source tagging, dedicated content owners, and a mandatory review cadence for each FAQ entry. Always record the exact origin of the data, such as the specific Zendesk ticket ID or product review ID.
Example validation tag for internal tracking: Proof tag: Owner product team | Verified: 2026-01-15
Typical Error: Injecting JSON-LD answers that make aggressive promotional marketing claims completely absent from the visible on-page text.
Technical Execution: Generators and Validation
A compact FAQ schema specifically formatted for ecommerce product pages reduces parsing friction for search engines and maximizes the chance of displaying organic rich results.
Standardizing the JSON-LD Payload
Why this matters: Consistent structured data helps search engines confidently surface product-level answers in SERPs.
JSON-LD is the preferred structured data format used by search engines to map and understand page content. You must use a minimal, production-safe pattern and populate the nested questions and answers exclusively with real, validated customer data.
Example template structure:
@context: https://schema.org@type: FAQPagemainEntity:
@type: Questionname: Does this product support international shipping?acceptedAnswer:
@type: Answertext: Yes, we ship to most countries. Shipping times vary by destination and are shown at checkout.
Typical Error: Appending promotional, keyword-stuffed, or excessively verbose answers directly increases the risk of complete removal from rich results.
Using a Generator at Scale
Why this matters: Manual authoring of thousands of individual FAQ JSON-LD blocks is remarkably slow, expensive, and error-prone for enterprise catalogs.
How to approach it:
- Source high-intent questions cleanly from support tickets, reviews, and return reasons.
- Normalize the raw text to plain sentences and systematically strip out unverified promotional language.
- Map each refined question to a specific product ID in your PIM or catalog mapping system.
- Store canonical answers alongside a unique source ID to ensure strict audit trails.
- Render the final JSON-LD payload per product using a robust templating engine, a dedicated microservice, or directly during your static site generation build process.
Validation and Pre-Deploy Checks
Why this matters: Malformed JSON-LD payloads can break pages, trigger manual search actions, or cause a sudden, catastrophic loss of rich results across the domain.
How to validate:
- Consult the Google Rich Results Test to verify technical eligibility.
- Automate a CI/CD pipeline gate (such as GitHub Actions utilizing standard validation scripts like schema-dts in TypeScript) that explicitly validates JSON syntax, field presence, and acceptable character limits before merging code.
- Deploy initially to a small staging product sample and actively monitor Google Search Console for coverage warnings, error spikes, and CTR changes.
Quality Assurance: Preventing Errors and Stale Data
This checklist framework gives QA and content operations teams a robust, structured workflow to prevent duplicate answers, fix data contradictions, and systematically remove stale claims while preserving overall product catalog integrity. This is especially vital when managing multi-language variants in international setups.
Prevent Duplicate Answers
Why it matters: Duplicate answers split search impressions, confuse users, and aggressively dilute overall page authority.
How to approach: Keep a singular canonical answer ID within your PIM and reference it dynamically from all product-level FAQ entries. Implement automated semantic matching and normalization rules to continuously merge near-duplicates. Ensure you consistently normalize variable tokens such as durations, local currencies, sizing formats, and policy names to prevent false negatives during automated deduplication.
Example: Two identical hardware color variants that share the exact same return policy must point to one canonical ID so that search impressions consolidate accurately.
Typical Error: Publishing near-duplicate answers across variants that differ only in minor punctuation or insignificant phrasing.
Fix Contradictions Across Product Variants
Why it matters: Contradictory claims drastically increase support desk workloads and can easily trigger internal compliance checks or legal issues.
How to approach: Systematically compare key terms, durations, and numeric claims across closely related SKU families. Run active contradiction detection utilizing rule-based checks and semantic embeddings to surface immediate conflicts, automatically pushing high-impact mismatches into a manual triage queue. Utilize direct hyperlinks to authoritative policy sources when resolving conflicts to maintain an ironclad audit trail.
Example: Automatically flag active storefront listings that mention conflicting warranty periods for items operating within the exact same parent product family.
Typical Error: Assuming variant data inheritance rules work perfectly without running actual post-publish verification.
Update Stale Shipping and Warranty Claims
Why it matters: Time-sensitive claims critically affect legal compliance, buyer trust, and overall SERP performance.
How to approach: Add a strict "last validated date" metadata field and set automated alerts for any FAQ items older than 90 days. Synchronize these answers tightly with your live logistics feed and utilize Shopify metafields for real-time data ingestion.
Example: Automatically unpublish any FAQ schema answers that reference deprecated holiday delivery promises until they are manually verified again by the logistics operations team.
Typical Error: Deploying highly time-sensitive delivery claims without attaching an associated "last validated date" trigger.
Measuring Impact and Maintaining Freshness
Maintaining FAQ schema quality intelligently prevents CTR decay over time and significantly minimizes the risk of generating low-relevance snippets that frustrate buyers.
Why this matters: Google Search Console is the ultimate source of truth for schema impressions, clicks, and rich result technical errors.
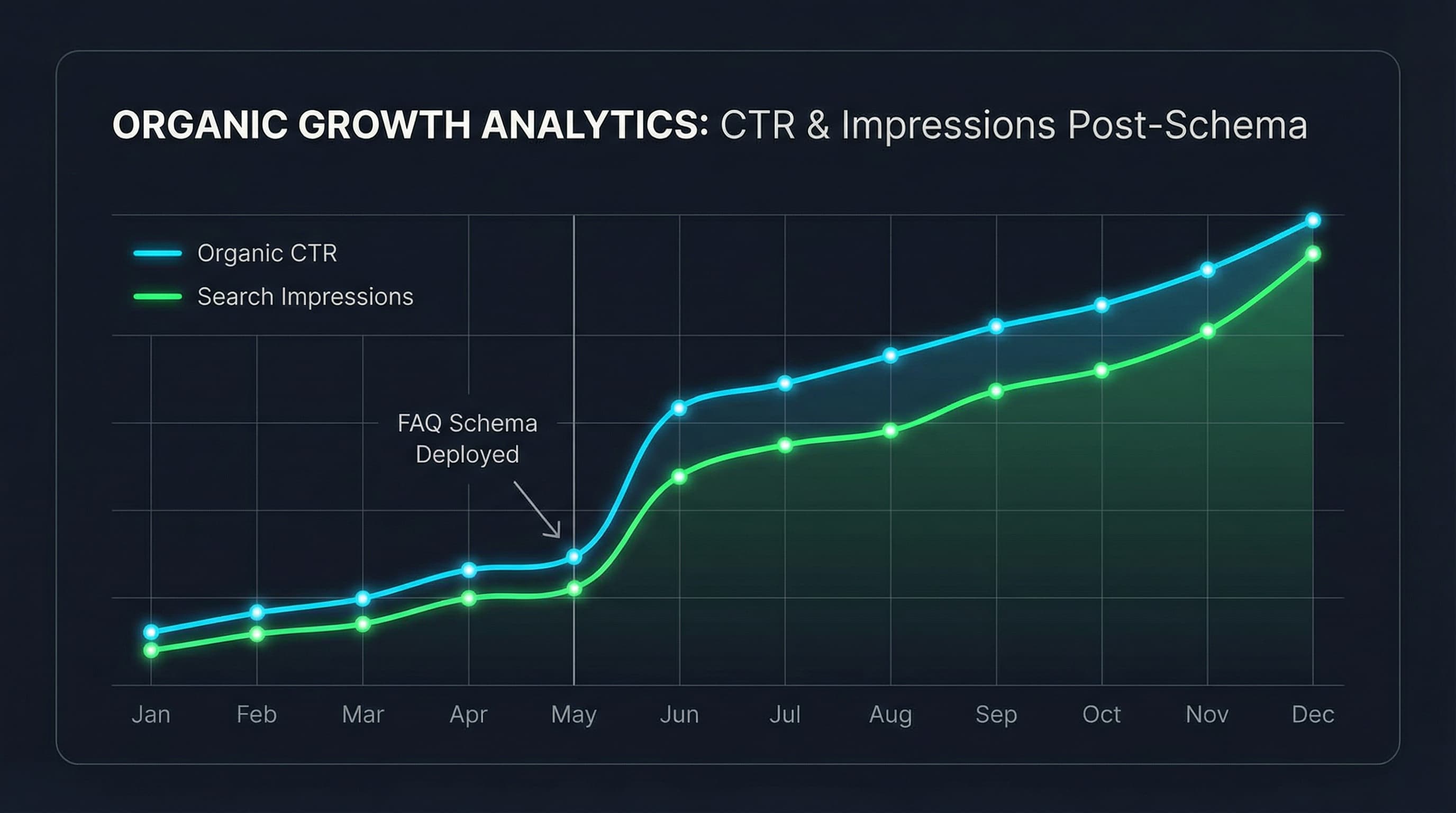
How to approach it: Navigate to the Performance report and actively filter by target page or specific query to compare a historical baseline period to the current active period. Export the raw data into Google Sheets or BigQuery for detailed grouped analysis, plotting CTR curves against impression volumes. Consistently monitor your rich results status inside the Enhancements report to catch parsing drops early.
Example: Filter by a specific core product page and directly compare the 30 days before and after your FAQ deployment to pinpoint exact CTR lift percentages.
Typical Error: Relying entirely on average, site-wide CTR metrics without properly segmenting the data by individual impressions per page.
Monthly Refresh Process
Why this matters: Regular monthly updates guarantee that published answers remain deeply relevant to current buyer concerns and sharply reduce stale or misleading content.
Step-by-step refresh cycle:
- Identify product pages actively generating FAQ rich results in the last 90 days, explicitly ranking them by total search impressions.
- Completely remove the visible UI FAQ block and JSON-LD schema for any discontinued SKUs, properly pointing the canonical URL to the active replacement pages.
- Extract the top newly emerging customer questions from support tickets, reviews, and returns covering the previous 30 days.
- Write highly concise, intent-driven questions alongside short factual answers, strictly validating them directly with a technical product SME.
- Test the payload thoroughly in staging utilizing structured data testing tools, and run randomized spot checks on the live frontend.
- Deploy the updates in staged geographic or category batches, monitoring Search Console closely for any newly introduced structured data errors or CTR shifts.
Handling Discontinued Items and Measuring CTR Lift:
When successfully handling discontinued items, ensure you completely sever the FAQ from the page template, apply a 301 redirect or canonical to a logical replacement, and firmly verify the removal inside the Search Console URL inspection tool. To measure CTR impact effectively, group your refreshed pages by impressions, export the raw performance data, and systematically compute the relative CTR lift before and after deployment.
Typical Error: Failing to cleanly remove schema on dead SKUs, causing irrelevant snippet rendering in SERPs and an eventual domain-wide CTR drop.
Automating FAQ Schema Sourcing and Governance
Extracting high-intent questions from massive unstructured data sets, clustering them accurately, and deploying them to the correct product metafields manually is simply impossible to scale across a large eCommerce catalog. ButterflAI detects real customer friction points from your support and review data, fully automating the creation, mapping, and strict governance of FAQ schema directly into your PIM or Shopify store. To stop guessing what buyers are asking and scale perfectly formatted structured data effortlessly, explore ButterflAI.